
In July, customers deploying NIXL, the NVIDIA Inference Transfer Library receive DDN Infinia support out of the box as part of the prebuilt NVIDIA Dynamo inferencing container.
Integration Overhead Is the Main Drag on Inference Deployments
Enterprises and GPU cloud providers assemble the hardware fast: thousands of GPUs, high-speed interconnects, accelerated networking. The drag comes from stitching software stacks together framework by framework and plugin by plugin, which consumes engineering cycles and introduces compatibility risk on every deployment.
Inference compounds the problem. Training runs hold a stable configuration for days or weeks; inference environments change constantly as models update, context windows grow, KV cache demand fluctuates, and data moves between storage, memory, and GPU. Each integration layer adds a failure point, latency, and a maintenance burden that scales with the fleet.
DDN Infinia feeds context to your GPUs straight from storage, so more of every watt goes to generating tokens and your AI factory earns more on the same hardware — and starting with NIXL 1.3 in July, that path ships in the box: the Infinia plugin is built into the official NVIDIA Inference Transfer Library package and the prebuilt NVIDIA Dynamo inferencing container, so you install NIXL or pull the NVIDIA Dynamo container, add the DDN client packages, and Infinia KV-cache acceleration turns on through configuration with no code changes.
NIXL Is How NVIDIA Delivers Inference Data Movement at Scale
NIXL, the NVIDIA Inference Transfer Library, moves data in distributed inference: disaggregated prefill and decode, multi-node serving, and large-context workloads that require efficient KV cache transfer. It provides GPU-native transfer and integrates with NVIDIA Dynamo, vLLM, LMCache, TensorRT-LLM and SGLang.
NVIDIA distributes NIXL as a Python wheel installable with a single pip install nixl. The wheel bundles Python bindings, required libraries, and supported plugins, so teams skip compiling from source and resolving dependency chains by hand. Inclusion in the wheel marks a component as core to NVIDIA’s inference ecosystem.
DDN Infinia Joins the Official NIXL Build Starting With 1.3 in July
The DDN Infinia NIXL plugin is now included in the official NVIDIA NIXL software distribution. Beginning with the NIXL 1.3 release in July, the plugin is packaged as part of the standard NIXL release and is also included in the NVIDIA Dynamo inference container. As a result, customers installing NIXL or deploying NVIDIA Dynamo using the official container have the Infinia plugin available out of the box and can enable it as part of their deployment.
| Before | After |
| 1. Install NIXL | 1. Install NIXL (or pull the NVIDIA Dynamo prebuilt container) |
| 2. Source and obtain the storage plugin separately | 2. Install the DDN client packages |
| 3. Validate plugin compatibility against the installed NIXL version | 3. Done |
| 4. Deploy and maintain the plugin independently across every environment |
For teams running Kubernetes, containerized inference clusters, and distributed GPU platforms, this removes an entire category of integration work that previously required specialist effort to bridge.
” With this new release, DDN Infinia now feeds context to the GPUs directly, so more of every watt goes to generating tokens, delivering dramatically better AI factory economics. The DDN Infinia connector ships inside the NIXL package and the Dynamo prebuilt container. Now with NVIDIA Dynamo and DDN Infinia your GPUs are efficiently serving on day one.” — Sven Oehme, CTO, DDN
Accelerate Inference and Increase Fault Tolerance with the DDN Data Intelligence Platform
Three architectural trends put the data platform at the center of production inference performance.
Agentic AI and Long context windows. Agentic AI workflows build context windows that reach millions of tokens, and KV cache volume rapidly exceeds GPU VRAM. Fast offload to and retrieval from backend storage is a prerequisite for serving long-context workloads at production throughput.
Fault tolerance. Production inference must survive node failures while holding in-flight request state. Persisting KV cache to durable backend storage lets the inference engine resume interrupted requests and hold service continuity through hardware failure.
Prefill-decode disaggregation. Running the compute-intensive prefill phase and the memory-bandwidth-intensive decode phase on separate GPU nodes lets each be optimized independently. Fast KV cache transfer between those nodes through backend storage makes disaggregation practical at scale.
DDN and Integration with Inferencing Engines
NVIDIA Dynamo orchestrates inference workloads, coordinating vLLM, SGLang, Mistral.rs, TensorRT-LLM, and other serving backends. Whenever one of those workloads offloads KV cache data, it issues the operation through NIXL. The DDN Infinia NIXL plugin then executes the transfer over two paths: by DMA between GPU memory (VRAM) and Infinia for KV cache offload, model artifact retrieval, and inference state management; and between CPU memory (DRAM) and Infinia for embedding retrieval, checkpoint loading, and pre-processing pipelines. Both data paths run over jRPC/RDMA for high-throughput, low-latency transport against Infinia’s distributed object storage.
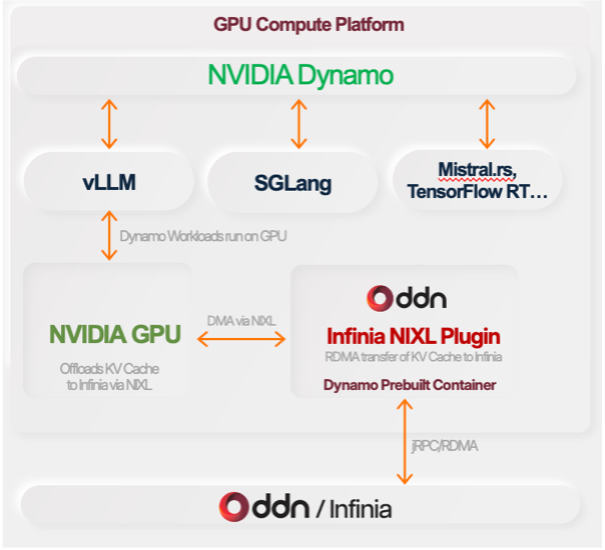
The Infinia NIXL plugin will also be functional without NVIDIA Dynamo, i.e. in cases where a model is served via standalone vLLM/LM cache/SGLang inferencing engine (without NVIDIA Dynamo orchestration), the Infinia NIXL plugin will be used to offload/onboard KV caches to/from GPU and the Infinia Data Platform
Figure 1. NVIDIA Dynamo reaches the DDN Infinia KV store through the NIXL plugin. KV cache moves GPU↔Infinia (VRAM) or CPU↔Infinia (DRAM) by DMA and jRPC/RDMA, bypassing CPU bottlenecks.
DDN Infinia NIXL Plugin: The Gold Standard for KV Cache Acceleration
- Zero-copy transfers. Pre-registered memory handles remove redundant copies for DRAM and VRAM operations; data moves directly between application memory and Infinia, skipping the staging buffers that add latency elsewhere.
- Parallel batch execution. Multiple transfers run concurrently via
red_async::BatchTask, delivering the throughput required to load large context windows, populate KV caches, and serve concurrent requests. - Asynchronous coroutine API. A coroutine-based async API keeps compute productive during data movement; background polling handles completion, and RAII smart pointers manage the lifecycle.
- Handle reuse. Memory handles register once and reuse across transfers, an efficiency gain for workloads that repeatedly access the same model artifacts or KV cache regions.
- Multi-tenant isolation. Cluster, tenant, and subtenant isolation are native, fitting the multi-tenant environments GPU cloud providers and enterprise AI platforms require.
- Configurable tuning. Service threads, buffer pools, and CPU affinity tune via parameters, environment variables, or configuration files, with application code untouched.
Incorporating the plugin drove NVIDIA to upgrade the NIXL framework to C++20, which brings native coroutines, improved concurrency primitives, and cleaner async patterns to every plugin and component in the ecosystem going forward. The full implementation is in the upstream repository: DDN Infinia NIXL plugin, Pull Request #1569, ai-dynamo/nixl.
“We designed the plugin to meet NIXL’s requirements head-on: clean component separation, Apache 2.0 licensing, validated dependency management, and a build flow that mirrors how customers actually deploy. The C++20 upgrade to the NIXL core came straight out of building a modern async plugin, and it made the whole framework better. Getting that into the official package sets up the next round of collaboration as NIXL evolves.”
— Manav Deshmukh, Senior Director of Engineering, DDN
DDN Is the First Storage Vendor in the Official NIXL Package
DDN is the first storage vendor whose NIXL plugin ships in NVIDIA’s official NIXL package and, by extension, in the prebuilt Dynamo inferencing container. For years storage sat at the periphery of GPU compute, a system data passed through on its way to the GPU. Accelerated computing includes the data movement layer as a first-class inference component. It follows DDN’s alignment with NVIDIA’s STX reference architecture and integration with NVIDIA BlueField-4 DPUs for DPU-accelerated storage processing.
DDN’s integration covers the rest of the stack too: users of vLLM, SGLang, and LMCache get the same plugin and results, and NIXL version upgrades bring Infinia updates automatically as part of the standard release.These new enhancements are also available to users of vLLM, SGLang, and LMCache using the same plugin. Infinia updates will automatically be available as part of the standard release.
Accelerated Data Now Ships With Accelerated Compute
The DDN Infinia NIXL plugin source is at github.com/ai-dynamo/nixl, PR #1569. For more information, visit ddn.com or contact your DDN account team. Check out the DDN Technical Blog Series on AI inference acceleration.