AI workloads are becoming more complex and dynamic, defined by bursty I/O, distributed data pipelines, and frequent checkpointing, demands that legacy storage often fails to meet at scale. Lustre, an open source parallel filesystem, has long offered the throughput needed to keep GPUs fed, which becomes critical as organizations train foundation models, run large-scale inference, and simulate real-world systems; scenarios where performance and agility can’t be compromised. In this era, data must move faster than ever, and cloud storage is expected to deliver the low-latency, high-speed access traditionally found only in high-performance computing.
To meet this need, Google Cloud created Google Cloud Managed Lustre, a fully managed parallel file system powered by DDN EXAScaler®, the industry’s leading high-performance Lustre distribution. By selecting EXAScaler®, Google ensures users benefit from unmatched throughput, low latency, and proven scalability tailored for demanding AI and HPC workloads. This service allows researchers, developers, and enterprises to deploy performance-optimized file systems directly within their Google Cloud environments, streamlining operations without sacrificing speed or control.
How Google Cloud Managed Lustre Works
Originally developed for the world’s fastest supercomputers, Lustre now serves as the backbone for some of the largest AI infrastructure deployments globally. Lustre has long been the standard for organizations with extreme I/O demands, ranging from government labs to life sciences and AI model training. With Managed Lustre, Google Cloud delivers a version of this file system that is optimized, elastic, and cloud native. This cloud native implementation supports sustained I/O bandwidths in excess of 250 GB/s per file system and scales performance linearly with compute. Combined with tight integration into GKE, Vertex AI, and TPUs, Managed Lustre enables high-throughput pipelines for workloads like multi-epoch LLM training, real-time fraud detection, and molecular simulations.
Google Cloud Managed Lustre provisions a POSIX-compliant file system optimized for AI workloads. Each file system consists of Metadata Servers (MDS), Object Storage Servers (OSS), and a scalable pool of Object Storage Targets (OSTs). These components are fully managed by Google Cloud, abstracting complexity while delivering parallel I/O performance traditionally available only in on-prem supercomputing environments.
This diagram illustrates the architecture of Google Cloud Managed Lustre, which is underpinned by DDN EXAScaler®, a production-hardened, enterprise-grade Lustre distribution. At the core of the system, EXAScaler® enables parallel file system performance with exceptional throughput, low-latency I/O, and scalability, essential for AI and HPC workloads.
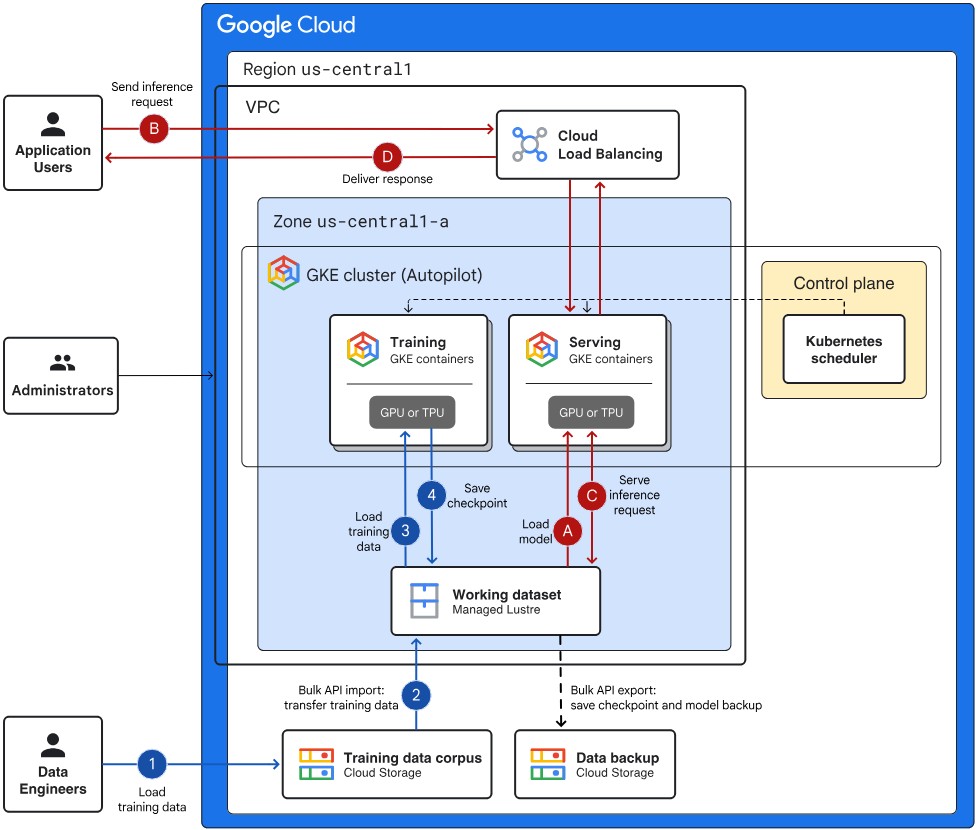
The architecture shows:
- Client nodes (e.g., compute instances or AI training servers) interfacing with the Lustre file system to achieve high-speed parallel access to data.
- Metadata and Object Storage Servers (MDS/OSS), deployed and managed within Google Cloud, running on EXAScaler® to deliver optimized storage performance.
- Integration points with Google Cloud services, allowing seamless deployment, elasticity, and operational simplicity in cloud-native environments.
By leveraging EXAScaler® Google Cloud ensures that Managed Lustre provides the same high-performance capabilities traditionally reserved for on-prem HPC systems, now available with the flexibility and scalability of the cloud. This includes optimized support for large-scale file operations, concurrent data access, and AI-specific workflows like checkpointing and data staging.
Key benefits include:
- Seamless integration with GKE, Vertex AI, and TPUs
- Fully managed setup, monitoring, and maintenance
- Petabyte-scale data throughput for training and inference
- Compatibility with AI pipelines requiring concurrent file access
For organizations already using DDN EXAScaler® or planning hybrid cloud strategies, Managed Lustre adds an accessible new layer to scale AI and HPC workloads beyond on-prem infrastructure.
DDN: Powering Performance from Data Center to Cloud
As the primary driver of Lustre innovation and deployment over the past two decades, DDN has worked with the largest AI and HPC environments to deliver unmatched file system performance. Our customers rely on DDN to accelerate time-to-insight across industries, from training large language models to running critical intelligence operations. DDN EXAScaler® is the industry’s fastest Lustre distribution, deployed at scale by customers like NVIDIA to support workloads requiring multiple TB/s+ throughput and lightning-fast checkpointing. As Lustre’s primary development force, DDN ensures consistency, security, and performance across on-prem and cloud deployments, giving customers a path to hybrid AI without sacrificing efficiency.
This new offering from Google Cloud is closely aligned with DDN’s own vision: building an end-to-end Data Intelligence Platform that brings together high-performance training, scalable inference, and real-time analytics under one intelligent data fabric. Whether you are moving AI workloads to the cloud, extending burst capacity, or architecting for hybrid AI infrastructure, this combination of DDN file system expertise and Google Cloud elasticity gives you the tools to go further, faster.
Unified Data Infrastructure for AI at Scale
To learn more about Google Cloud and DDN’s partnership and how to architect AI workloads with cloud-native Lustre and DDN’s Data Intelligence Platform, visit our joint solution page or speak to a technical expert.