
The Context Revolution is Here
The AI landscape has fundamentally shifted. What started as simple chatbots has evolved into sophisticated reasoning systems that process massive contexts – the set of tokens (text, code, or data) the model “remembers” and uses to generate accurate, relevant output – and deliver human-like insights. Context is what the model knows in the moment. It’s the “working memory” that determines how well it understands, reasons, and responds – making it a foundational concept in designing performant AI applications.
However, this sophisticated reasoning utilizing contexts comes with a hidden waste, one measured not just in computational cycles, but in real business impact. The core problem isn’t technical, it’s economic. Every time your AI system recomputes context, instead of leveraging cached data, you’re paying a “GPU tax”: wasted cycles on highly expensive hardware that could be serving more customers or reducing infrastructure costs. Longer context = more tokens to process = more compute = longer latency = higher cost.
Amazon found that every 100ms of latency costs them 1% in sales. Now multiply that across millions of AI interactions daily, with context windows that have grown from hundreds of tokens to hundreds of thousands, and you understand the true cost of context in modern AI.
The Economics of AI Reasoning
Today’s AI reasoning models think through problems iteratively. A customer service AI analyzes conversation histories, retrieves documentation, reasons through solution paths, then formulates responses. Each step requires maintaining and expanding context, leading to exponentially growing computational demands.
The economic consequences are significant:
- Agentic AI systems use 100x more computation than traditional models (c/o NVIDIA CEO Jensen Huang)
- User satisfaction drops 16% for every additional second of latency
- To make matter worse, context windows are expanding from 128K to over 1M+, driving a proportional increase in KV cache requirements
- One poor AI response can drive 30% of customers to abandon a purchase.
Core Insight #1: Recomputing the same context wastes resources, inflates costs significantly, and slows AI-driven business outcomes.
The Solution: KV Cache
So, how do we solve this economic problem with a technical, AI infrastructure-based solution? Let’s analyze the AI reasoning model calculation process to understand what needs to be addressed.
- First, transformer models process text by calculating how each word relates to others using attention. This produces Key and Value (KV) tensors that capture context and meaning.
- Second, in the prefill phase, the model builds these tensors from the input prompt.
- Third, in the decode phase, it generates new tokens using that context.
Without something to “remember” this information, the model repeats the same calculations for every request. This wastes compute, slows performance, and increases cost.
The solution? KV Cache. KV Cache eliminates the need to constantly recalculate context by storing (caching) the tensors after they are first created. The model can then reuse them instantly, accelerating inference and reducing resource demands. As context lengths grow into the millions of tokens, caching becomes essential.
Core Insight #2: Having the context cached eliminates wasted resources, reduces costs, and accelerates AI-driven business outcomes.
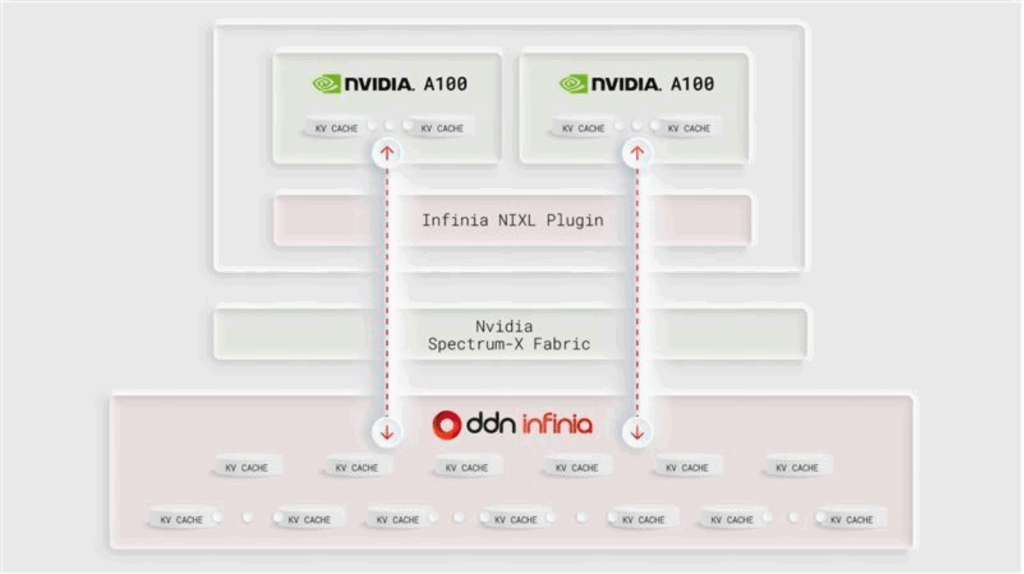
DDN Infinia + KV Cache = Unmatched Performance
DDN Infinia was engineered specifically for AI reasoning systems’ high-concurrency, low-latency requirements, providing the following customer benefits:
- Unrivaled Scale: DDN is the only Data Intelligence Platform that significantly scales to deliver enterprise-grade AI performance. DDN’s IO500 results consistently demonstrate industry-leading results that translate to higher GPU utilization and faster Time to First Token (TTFT).
- Sub-Millisecond Latency:
- DDN Infinia: Under 1ms retrieval latency
- Traditional cloud storage: 300-500ms
- Vector databases on slow storage: 100-200ms
- Massive Concurrency: 100,000+ concurrent AI calls per second with consistent performance.
- GPU-Optimized: Purpose-built integration with NVIDIA GPUs, DPUs, and frameworks ensures accelerators spend time thinking, not waiting.
But most importantly: KV Cache is directly integrated into DDN Infinia. That means that customers can get the benefits of Infinia PLUS the benefits of KV Cache, accelerating model runtimes and significantly reducing costs.
DDN Infinia & KV Cache in Action
DDN ran a realistic test, serving conversations with over 100,000 tokens (becoming common in Enterprise AI). The test is querying a large table that is passed on as part of context. All tests are using disaggregated inference.
Here’s the configuration details:
- Compute: 2 NVIDIA A100 GPUs, 80GB total
- Storage: 6 DDN Infinia nodes running on Google Cloud Platform (GCP)
- Training Model: Qwen3-32B
- Software Framework: LMCache
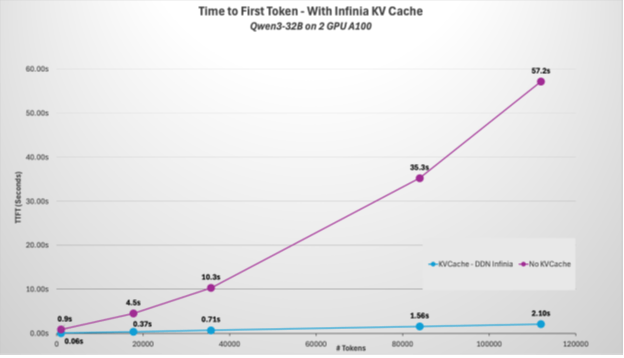
Here’s how the performance stacks up:
| Approach | Context Length | Processing / Loading Time | GPU Usage / Utilization |
| Traditional (Recompute Every Time) | 112,000 tokens | 57 seconds | High compute demand, low efficiency |
| DDN Infinia with KV Cache | 12,000 tokens | 2.1 seconds (25X faster) | Optimal, focused on generation |
This isn’t just a performance improvement – it’s a fundamental cost structure change. What may be moderate 15x increase in a small context of 1045 tokens becomes a massive 27x increase in a larger 112k context. Even if we take the medium context of 35k tokens – it is a 22x improvement which means you will need 1/22 of GPU time to answer the customer’s request.
Going Further: Per-Million Token Savings
Advanced reasoning models like OpenAI’s O3-Pro provide economic reference point for what the cost savings are. It clearly defines market price. Input tokens are derived from your prompt and output are the model response. The following is the published pricing:
- Input tokens: $20 per million
- Output tokens: $80 per million
Traditional Recompute Model (1M token context, 5 interactions):
- Context reprocessing: 5M input token charges
- Cost per conversation: $100 in input fees alone
- Plus: GPU compute costs for redundant processing
DDN-Accelerated KV Cache Model:
- Initial cache generation: $20 (one-time cost)
- Subsequent retrievals: Near-zero computational cost
- Cost savings: $80 per conversation (75% reduction in input cost)
For an Enterprise processing 1,000 conversations daily, DDN’s KV caching reduces token processing costs by $80,000 daily ($29M annual) while improving response times.
A Real-World Example of the Context Problem
Consider how often users return to a chat, hours or even days later, expecting the system to pick up where it left off. Without KV Cache, the model must reprocess the entire conversation history each time, burning through valuable GPU cycles just to recall context.
Think about a common customer support flow:
- Morning: Customer uploads documentation, explains a complex issue which generates 5,000+ tokens
- Afternoon: They return to answer follow-up questions regarding the same issue
- Next Day: They return to ask implementation questions regarding the same issue
Without KV Cache, the system reprocesses the entire history each time, leading to delays of 10 seconds or more just to restore context. Without caching, that’s 15,000+ tokens reprocessed per interaction, adding 10+ seconds in latency and burning GPU time.
With KV Cache and DDN Infinia, that context is instantly accessible. Responses remain immediate and relevant – no matter when the customer returns.
- 75% reduction in input token processing costs achievable through proper KV caching with DDN – translating to $80,000 saved daily
- DDN optimized GPU utilization increased efficiency by 50%, translating to millions in savings
Core Insight #3: Integrating KV Cache with the performance of DDN provides optimal economic results!
The Strategic Imperative
The trend toward larger contexts and sophisticated reasoning has arrived. Models are moving to 1M+ token contexts with reasoning becoming standard. Organizations using traditional storage infrastructure for AI workloads pay a “GPU tax” by wasting GPU cycles, extending response times, degrading experiences. This compounds with every query, user, and AI capability expansion.
DDN Infinia, utilizing KV Cache, eliminates this waste by delivering industry-leading Time-To-First-Token (TTFT), maximizing GPU utilization, and scaling with today’s AI demands, providing a real customer benefits and outcomes, such as:
- Over 27X faster model runtime
- Nearly 100% GPU utilization compared to 60-70% with legacy storage
- Sub-millisecond latency at enterprise scale
- 75% reduction in input token processing costs, unlocking up to $30M in annual savings on a $100M investment
The AI reasoning revolution is here. Ensure your infrastructure captures its full potential.