By Nasir Wasim, Senior AI Solutions Consultant
Two years ago, I watched a senior ML engineer with 5 years of computer vision experience spend his entire day playing digital detective with filenames like “product_images_FINAL_vs3_Actually_FINAL”. What I witnessed that day revealed a hidden productivity crisis destroying ML teams everywhere which is a metadata problem that’s eating your engineering budget.
That day changed how I think about ML infrastructure forever. I realized I wasn’t watching a technical problem; I was watching a senior engineer do intern level work and it’s happening at most of the companies.
How Metadata Makes or Breaks ML Pipelines
Every data scientist knows the 80/20 rule: 80% data prep, 20% modeling. What those studies miss is the painful reality of that 80%. Sure, some of it is cleaning, duplication and feature engineering. But I have spent many years watching ML teams, and the biggest time sink is not messy data rather it’s the treasure hunt.
Let me tell you more about the ML engineer (let’s call him John). A computer vision specialist working on product recommendations at a Fortune 500 retailer. He knew exactly what he needed: product images from their mobile app uploads, the high-resolution ones with complete metadata from Q2, processed through their updated computer vision pipeline. But finding it? That turned into an archaeological expedition through folders named things like ‘product_imgs_final_v2’ and ‘mobile_uploads_march_DO_NOT_DELETE’
The Real Cost of Poor Data Discoverability
After two days of digital archaeology, he finally locates what looks like the right/quality dataset, which is 1.2 million product images from their mobile app uploads. He starts training his model, burns through $800 in GPU credits, and gets promising initial results. The model accuracy numbers look good enough to present to leadership.
Then one of the senior members from the data engineering team drops by his desk. ‘Oh, you’re using mobile uploads from 2022? Just so you know, we had a bug in the image resizing pipeline that quarter. Everything got compressed to 480p instead of the full resolution. Now his model has been learning from systematically degraded images for a week.
This is not a fabricated or hypothetical story. I’ve seen this exact scenario play out at different companies. The GPU costs are just the visible expense, the real damage is the two weeks of ML engineer time, the delayed product launch, and the fact that he now becomes suspicious and questions every dataset he touches.
The worst part? all the information data engineer shared was known, it was documented in a Slack thread from eight months ago, mentioned in a Jira ticket, and briefly noted in someone’s personal notebook. But metadata scattered across chat logs and tribal knowledge might as well not exist when you’re racing to ship a feature.
Gartner pegs poor data quality costs at $12.9 million annually per organization. That’s probably low. When your senior engineers spend more time being detectives than building ML systems, you are not just losing money; instead, you are losing the game.
Source: https://www.gartner.com/smarterwithgartner/how-to-improve-your-data-quality
Metadata: The Foundation of ML Pipelines
Three months after John’s worked with annotation teams to label the 1.2 million images, his company hired a new VP of Engineering who’d come from Netflix. First thing he did? mandated that every dataset needed what he called a “data passport” a complete record of its journey through their systems.
Within six months, they’d built something that looked more like a database than a file system. Every image upload got tagged automatically: device type, upload timestamp, user demographics, processing pipeline version, even the network conditions during upload. When new product photos came in, the system could instantly route high-quality shots to the recommendation engine while flagging blurry or corrupted images for manual review.
The transformation was stark. Remember John’s two-week archaeological dig? Now he types a query: “product images, mobile uploads, full resolution, Q3 2023, fashion category.” Results in 0.3 seconds. More importantly, when his model’s performance drops, he can trace it back to the exact data batch that caused the issue.
Organizations treat metadata as an afterthought, a “nice-to-have” feature tacked onto their storage infrastructure. But the most successful ML teams I’ve worked with flip this thinking entirely. They treat metadata as the nervous system of their data ecosystem, the critical infrastructure that makes everything else possible.
Think about what metadata enables in a mature ML pipeline:
When metadata captures not just what data was used, but the exact preprocessing steps, hyperparameters, and environment configurations, reproducing results becomes trivial. The infamous “but it worked on my machine” problem disappears.
The Infrastructure Reality Check
Now, here’s where rubber meets the road. Most object storage systems give you basic tagging capabilities, maybe 10-20 tags per object if you’re lucky. That sounds reasonable until you realize that a single ML training run might generate metadata across dozens of dimensions: Model metadata| Data metadata | Performance metadata | Infrastructure metadata | Governance metadata | operational metadata, etc.
Suddenly, your “adequate” system becomes a straitjacket. You’re forced to choose between rich metadata and system limitations, and rich metadata loses every time.
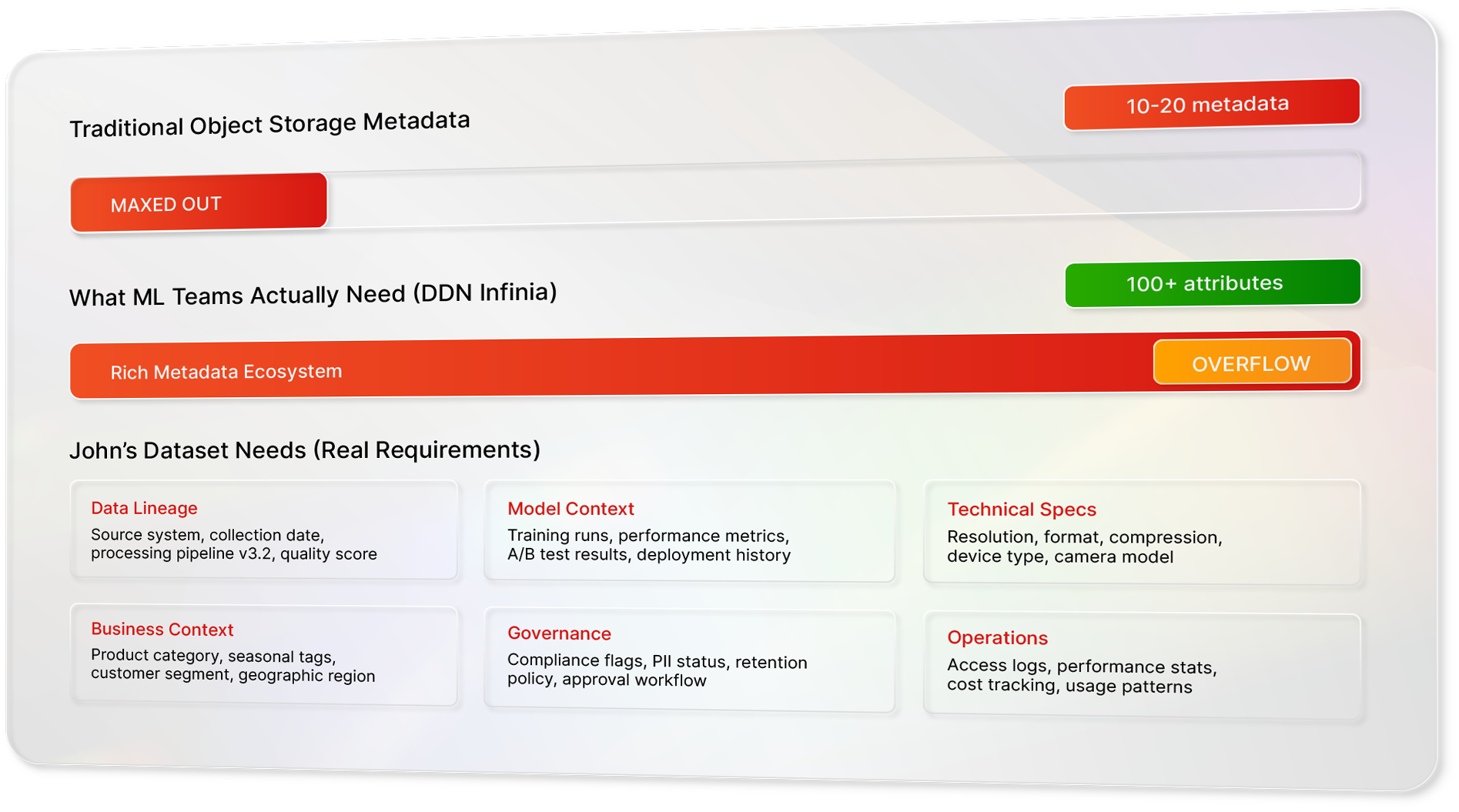
Where Infinia Changes the Game
This is where Infinia’s approach becomes genuinely transformative. When we claim support for “thousands of tags per object,” we are not just talking about storage capacity, we are talking about enabling an entirely different class of ML workflow. Let me show you what this looks like in practice. Imagine uploading a trained model to your object store with metadata where every critical piece of information attached directly to the object itself:
Now, instead of archaeological expeditions, your team performs surgical queries:
- “Find all datasets processed through the v2.1 augmentation pipeline that were affected by the image compression bug in March 2023”
- “Find all ImageNet datasets with annotation-confidence-score above 0.95 and zero known labeling errors from the past 6 months”
- “Show me all ResNet models with validation accuracy above 92% trained in the last quarter”
Each query returns not just the objects, but their complete context, enabling informed decision-making at the speed of thought.
In most of the legacy systems, metadata is not treated as important. You end up with engineers spending hours digging through folders or writing one-off scripts just to figure out where the data came from and how it was processed or whether it is even usable or not, it’s direct result of how traditional architectures are built. They serialize access, route everything through central controllers and treat the data as opaque blobs.
DDN Infinia takes a fundamentally different approach. It is built around the distributed, client –driven that pushes the intelligence to the edge. Instead of routing everything through a central gateway, the client SDK talks directly to the exact nodes where the data lives, which means parallelizing access at scale. That makes the metadata queries feel instantaneous, even across billions of files.
A Practical Implementation
For teams ready to make this transition, the path forward is clearer than you might think. Start by auditing your current metadata practices:
- Inventory your current tagging: How many attributes do you typically capture? What’s missing?
- Map your search patterns: What questions do your data scientists ask most frequently?
- Identify your pain points: Where do you spend the most time on data archaeology?
- Design your metadata schema: What would your ideal object metadata look like?
- Test the infrastructure: Can your storage system actually support your metadata ambitions?
The Bottom Line
John’s team ships models 5x faster after that implementation. Not because they got better engineers or bigger budgets, but because they stopped treating every deployment like an archaeological expedition.
Metadata capability is the real differentiator between ML teams that scale and ML teams that struggle. It’s the difference between data scientists who innovate and data scientists who excavate. It’s the difference between ML operations that accelerate business outcomes and ML operations that consume resources without delivering proportional value.
The organizations that recognize this early, that invest in metadata as a first-class infrastructure concern, won’t just have faster ML pipelines but also, they’ll have smarter ones. And in a world where the speed of insight increasingly determines competitive advantage, that’s not just an operational improvement, it’s a strategic imperative.
The question is not whether your organization will eventually prioritize metadata-driven ML pipelines. The point is whether you’ll lead that transition or follow it. To learn more, visit our website.