As companies scale up their AI factory workloads, Retrieval-Augmented Generation (RAG) pipelines are scaling to tens and hundreds of millions of embeddings. There is a direct relationship between increasing enterprise knowledge available to AI agents and the size of vector embeddings. As scale increases, vector ingestion and indexing become the bottlenecks where users feel the pain of out-of-date knowledge bases and taking days to weeks to ingest data into their vector database. Enterprises endeavor to provide the best end user experience with fresh, accurate, and comprehensive responses, but CPU-only indexing pipelines and local-storage–centric architectures make it impractical to update data fast enough to keep knowledge bases current. Moreover, GPU-accelerated indexing enables faster database re-indexing because of pipeline updates or data drift, reducing maintenance downtime.
DDN believes that scalable vector indexing for RAG is a system problem, not just a compute problem. Sustaining RAG quality at enterprise scale requires both GPU-accelerated vector indexing and highly scalable storage.
To show the differences between CPU and GPU performance, we ran several tests reflecting the turnaround time for adding new documents to an enterprise knowledge base ready for use by AI agents. We baselined the performance using the Miracl dataset running against a Milvus 2.5 Vector Database with embeddings generated via NVIDIA llama-3.2-nv-embedqa-1b-v2 running against 32 vCPUs. All storage used was DDN Infinia 2.2, using the S3 API as the communication method, including for the backing store for Milvus. We ingested up to 106M embeddings (~2TB of multimodal data) into the vector database with data hosted on Infinia.
The first test was a comparison of 32 vCPUs Vs. NVIDIA cuVS with a single NVIDIA L40S GPU.
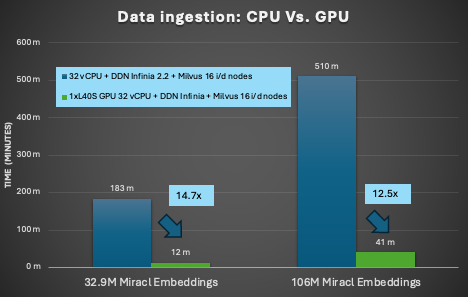
Compared to a CPU-only baseline, the L40s GPU-accelerated indexing delivered 14.7x faster time to complete the 33M embeddings, and 12.5X faster times on the 106M embeddings!
We then upped the ante by testing the 106M Miracl embedding set against both single and dual NVIDIA RTX PRO 6000 GPUs and measured both ingestion and indexing times. In order to provide a better performance envelope, we upped the number of vCPUs to 64 on the CPU benchmark. The results are quite dramatic.
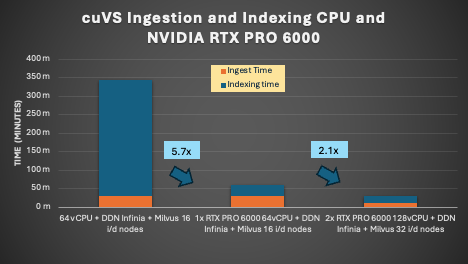
Compared to the prior chart, we see several interesting bits of data:
First, the NVIDIA RTX PRO 6000 reduced the index time compared to the CPU by 11.6x, and moving from single to dual GPUs showed strong improvements, reducing the index time by 18.4x, showing how distributing the indexing workload can scale efficiently.
Second, we decreased the ingestion time linearly by scaling out Milvus from 16 to 32 nodes. This is critical as ingestion time can become the bottleneck, taking up 50% of the end-to-end time, after indexing is accelerated by GPUs. This can be directly attributed to the ability of the Infinia server to handle the S3 calls generated by all the Milvus nodes in a highly parallel manner. This effectively enables the overall ingest time to reduce linearly as more Milvus nodes are added.
Sidebar: Storage performance has a large impact not just on ingestion, but also on indexing as well. When indexing, the data follow a path of first having the Miracl data pulled from Infinia via S3 into Milvus. Then Milvus parses the data and writes to its own internal data area (also hosted on Infinia). Then indexing nodes read the data back out, processes it, and writes the index files back into the Infinia system. There are multiple reads and writes happening simultaneously on each indexing node during this process. Because there were up to 32 indexing nodes working at once during this test (in the 2x NVIDIA RTX PRO 6000 test), the ability to handle lots of parallel requests and the associated metadata becomes a critical factor in producing high performance results.
The combined performance of NVIDIA GPUs with cuVS and DDN Infinia storage working together directly address how to enable customers for success:
- Near Real-time search performance by offloading vector indexing to the CPUs.
- Unlock continuously fresh RAG systems with rapid re-indexing.
- Maintain always current knowledge bases without compromising availability.
- Scale multilingual and multimodal data refresh efficiently.
- Drive real-time recommendation and personalization from live user behavior.
These results are enabled by DDN Infinia, which provides S3-compatible access with performance comparable to local NVMe while scaling to petabytes across nodes—removing the traditional trade-off between indexing speed and storage scale.
Together, NVIDIA cuVS and DDN Infinia restore the core customer promise of RAG: fresh data, fast updates, and consistent retrieval performance as data scales. At enterprise scale, GPU-accelerated vector indexing is no longer an optimization—it is foundational infrastructure.