By Moiz Kohari, VP of Enterprise & Cloud Programs
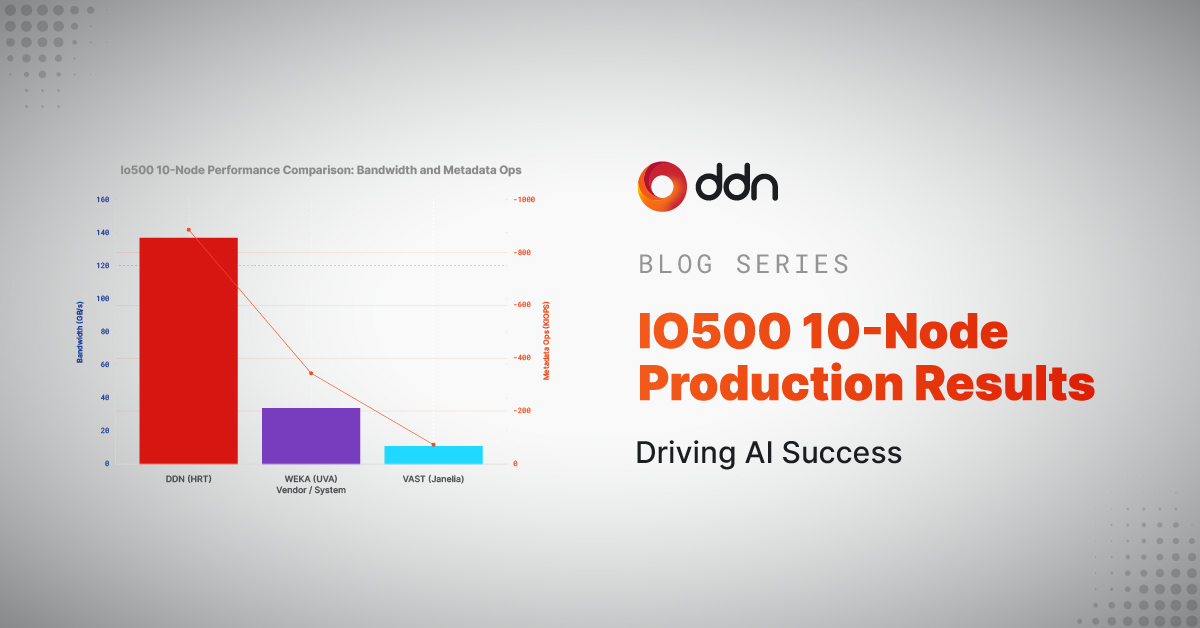
Few metrics capture real-world AI storage performance as clearly as the IO500 benchmark. In the latest IO500 10-Node Production rankings (ISC 2025), the results read like a roll-call of DDN’s success. DDN-powered systems account for 7 of the top 10 positions, and 10 of the top 24, on this prestigious list. No other storage vendor comes close. This dominance is not a statistical quirk – it reflects DDN’s balanced engineering that excels in both raw throughput and metadata handling. In practical terms, DDN EXAScaler® demonstrates it can move terabytes of data per second while simultaneously sustaining millions of small-file I/O operations, exactly the mix demanded by today’s converged HPC and AI environments. From quantitative finance and telecom to academia and national labs, organizations with vastly different AI workloads are converging on the same conclusion: DDN delivers the fastest, most balanced data platform available. This broad adoption, coupled with repeatable top-tier results, provides powerful validation of DDN’s engineering excellence and maturity at scale.
Contextualizing the Benchmark
It’s important to put the IO500 results in context. The IO500 benchmark is designed with synthetic, metadata-heavy HPC patterns in mind – patterns that are not identical to modern production AI workloads. At first glance, Intel’s DAOS file system claims the top IO500 score by tuning aggressively for the benchmark’s mix of tiny file operations and MPI-driven access. But that headline result hides an inconvenient truth: DAOS thrives in a narrowly optimized scenario and lacks the ecosystem maturity needed for real-world AI deployment. It offers no robust hybrid cloud integration, multi-tenant security, or enterprise compliance features – a non-starter for serious AI in industry, regardless of its raw numbers.
Real AI pipelines – from autonomous driving R&D to large-language model training – simply don’t look like synthetic HPC benchmarks. They demand sustained high throughput on large datasets, with occasional metadata spikes rather than constant small-file IOPS. This is where DDN’s design philosophy shines. DDN EXAScaler® is architected to deliver balanced performance: massive sequential bandwidth to feed GPU farms at full speed, plus the ability to handle metadata surges (for example, during checkpointing or ingesting millions of small features). The impact of this balance is evident both in the field and on the IO500 list. DDN EXAScaler® has delivered over 3x the performance of WekaFS and more than 10x that of VAST Data on the same AI workload. This isn’t just theory – it’s reflected in the IO500 results, where neither Weka nor VAST appear anywhere near the top ten. In short, DDN marries benchmark-proven throughput with real-world resilience.
Real World AI Workloads
Real-world AI workloads typically involve training large models across hundreds or thousands of GPUs (imagine clusters of 1000+ NVIDIA A100/H100 GPUs) all sharing a common data hub. To keep such expensive compute fully utilized, the storage system must handle multiple demanding I/O patterns simultaneously. It needs to support:
- High-throughput data ingestion – streaming massive datasets fast enough to feed training processes in parallel.
- Fast model checkpointing – writing and reading multi-terabyte snapshots without delay.
- Metadata-intensive access – managing millions of small files (e.g. feature sets or model weights) as AI jobs iterate.
- Concurrent mixed workloads – training, data pre-processing, and inference might all hit the storage at once in a production pipeline.
In production AI pipelines, huge sequential reads and writes dominate the core training phase – thousands of GPUs need a firehose of data. Metadata surges do occur, but at the edges of the workflow (during setup, checkpoint, or finalizing models), not as a continuous torrent. This is a crucial distinction: a storage system must excel at throughput without being derailed by periodic metadata bursts. DDN’s architecture, proven in the world’s fastest supercomputers, was built for exactly this balance. (Notably, the same DDN EXAScaler® flash technology that drove CINECA’s Leonardo system to a record 807 GiB/s bandwidth in HPC is powering enterprise AI deployments with similar success.)

It’s worth noting that the competitors often had to throw significantly more client processes and hardware at the problem to reach even those numbers. The bottom line: DDN’s platform not only delivers unrivaled peak speeds, but it also does so with efficiency and headroom to spare. In real-world terms, this means DDN can keep more GPUs busy with less infrastructure – a direct translation to faster AI outcomes.
The Business Value of DDN Infinia
In a world where AI infrastructure is one of the most expensive investments an organization can make, storage performance isn’t just a technical metric – it’s a business driver. Every minute a GPU sits idle waiting for data is wasted capital. DDN ensures that data is never the bottleneck, turning I/O performance into a force multiplier for the entire AI stack.
Independent benchmarking and customer data have shown that to match DDN’s AI platform throughput, competitors must scale out dramatically. For example, one test found that a WekaFS solution required roughly double the hardware footprint – over 3,400 client-side processes versus ~1,600 for DDN – to approach the same throughput. VAST Data’s architecture needed nearly five times the scale (on the order of 7,600 client processes) to hit similar performance levels. The implications for cost are enormous. Over a typical 3-year TCO horizon, a DDN Infinia deployment was projected around $154M (including infrastructure and operational costs). The equivalent Weka configuration was estimated at roughly $328M, and the VAST setup at an eye-watering $743M. In other words, DDN’s solution can save on the order of $174M–$589M over three years compared to achieving the same performance with those alternatives. That is hundreds of millions of dollars freed up – capital that can be redirected to acquiring more GPUs, funding AI development, or accelerating new initiatives, instead of being eaten up by an inefficient storage footprint.
The benefits don’t stop at infrastructure savings. Because DDN feeds data to GPUs so much faster, overall GPU utilization climbs significantly. Many DDN customers report on the order of a 15% improvement in GPU efficiency after eliminating I/O wait times. On a 1,000-GPU cluster (which might represent a $30M investment in compute), that uplift is equivalent to getting an extra $4.5M worth of productive work from the same hardware every year. Over three years, that’s about $13–14M in additional value created simply by keeping expensive accelerators busy. This is one reason why NVIDIA itself relies on DDN storage to power its internal AI superclusters – the fastest GPUs in the world are only as effective as the data pipeline feeding them.
Faster storage also means faster experiment cycles. DDN Infinia has been shown to cut AI model training times by around 25%, thanks to superior bandwidth and metadata performance speeding up data preprocessing, training iterations, and checkpointing. For an AI development team, that could mean finishing training in 3 days instead of 4 – accelerating research and time-to-results. Over the course of a project, these gains add up to dramatically shorter time-to-market for new AI capabilities. In fact, organizations leveraging DDN have typically seen launching new AI services 2–3 months sooner than they otherwise could. For a business, being three months ahead of the competition with a revenue-generating AI product can translate into an incalculable advantage (easily tens of millions in potential revenue or savings). In sum, DDN doesn’t just eliminate I/O as a performance bottleneck; it turns storage into a competitive advantage – delivering more results, faster, for less cost.
Why Competitors Trail So Far Behind
The stark gap between DDN and other solutions is not a coincidence – it comes down to architectural choices and experience at scale. DDN’s parallel file system heritage (rooted in Lustre and refined over decades of HPC leadership) was built to deliver extreme performance on both axes: throughput and metadata. Competitors often excel in one dimension but falter in the other. For instance, WekaFS is a modern, high-performance file system that can handle metadata in bursts, but to drive very high throughput it relies heavily on client-side resources and network optimizations. As a result, scaling Weka to DDN-level performance typically means adding many more clients and CPUs, which introduces complexity and diminishing returns. This was evident in benchmarks where Weka required significantly more nodes to reach a fraction of DDN’s IO500 score. In practical deployments under mixed AI workloads, we’ve seen DDN outpace Weka by factors of three or more, simply because DDN’s efficiency leaves far less performance “on the table.”
VAST Data, on the other hand, has a unique disaggregated storage architecture great for large unified datasets, but its system favors capacity and ease of use over sheer performance at scale. The IO500 results and real-world tests show that VAST cannot sustain the concurrency and small-file operations at the level a DDN system can. In a head-to-head scenario simulating AI training workloads, DDN delivered an order of magnitude higher throughput than a comparable VAST configuration. VAST’s limited metadata handling and reliance on specialized hardware ultimately cap its performance in these environments, explaining why its scores lag so far behind. In fact, neither Weka nor VAST appeared in the top ten of the IO500 10-node list – a clear indication that their architectures hit a wall when faced with the kind of demanding, balanced I/O that modern AI workloads generate.
Even the one storage technology that surpassed some DDN results in raw IO500 scoring – Intel’s DAOS – illustrates the gap in real-world readiness. DAOS achieved impressive numbers by optimizing for the benchmark’s patterns, but it remains a niche HPC solution lacking critical enterprise features and support. It doesn’t provide the robust data management, hardware compatibility, and end-to-end support that enterprises require when deploying AI at scale. In contrast, DDN Infinia and EXAScaler® are full-featured, enterprise-hardened solutions. They integrate with cloud and on-premises workflows, offer fine-grained security and multi-tenancy, and come with professional support services that global industries depend on. DDN’s competitors trail behind not just in performance, but in the proven ability to deliver at scale, day in and day out, on real production AI systems.
Conclusion
AI is transforming every industry, and it is doing so at a pace limited only by how fast we can feed data to our models. The IO500 10-node benchmark and other real-world tests underscore a decisive fact: DDN delivers that data faster, more reliably, and at greater scale than anyone else. By dominating performance metrics and demonstrating tangible business value (through lower TCO, higher GPU utilization, and quicker outcomes), DDN EXAScaler® and Infinia solutions have set a new bar for AI storage.
For CIOs and CTOs building out AI infrastructure, the message is clear. A balanced, high-performance storage platform like DDN’s isn’t just about bragging rights on a benchmark – it’s about enabling AI success. It means your million-dollar GPU clusters spend their time learning and inferencing, not waiting on I/O. It means your data scientists can iterate faster and your organization can deploy new AI capabilities in weeks instead of months. And it means you can accomplish all this while spending a fraction on infrastructure compared to less efficient alternatives. In an era where every competitive edge matters, DDN has proven that the right storage strategy can propel AI initiatives to new heights. Choosing DDN is choosing performance without compromise – turning the former bottleneck of storage into a catalyst for innovation and business growth. Use our GPU Efficiency ROI Calculator to see how much performance you’re leaving on the table and what you could be saving.