Jülich’s Sebastian Lührs spoke at DDN’s bi-annual user group about the I/O Acceleration in a modular HPC environment. His presentation, held virtually at Supercomputing 2021, offers a glimpse into the latest research at JSC using their new high-performance storage tier which supports three of the largest supercomputers on the Top500 list, delivering a total of 2TB/sec total throughput.
See an extract from the I/O Acceleration in a Modular HPC Environment session below and click play to watch the entire session.

Modular Supercomputing- what does it mean?
We follow a modular approach at Jülich for Exascale computing, and we look at how I/O can be accelerated in such a modular environment across a range of applications.
Typically, if you deploy a system on your site, you have one monolithic system, maybe a cluster or a system which focuses on AI processing. Every few years at Jülich, we set up a new system, which we need to connect to the other modules. For example, we could have a general purpose GPU cluster, which serves the HPC community, but there are applications which can benefit from very high performance – so we call this a “booster” system, equipped with a large number of GPUs inside.
We want users to be able to use these modules within their applications – not just having two separate systems communicating via the file system. As we heard this morning, you could have an approach with one module which is built to focus on AI, also a data analytics module, and maybe there’s also running a simulation in parallel, which is also connected to the cluster. And in this modular environment, an important module is the storage device: Data might not directly come to our mind when we think about computing devices, but is a very important topic when it comes to dealing with the dataset.
Data access and data management needs to be integrated in this modular approach, which is what we follow for the JUWELS system which runs on our site.
Comparing HPC and AI Workloads
AI workloads place new demands compared to HPC workloads, which is why we need I/O acceleration on our side, to meet a range of user needs. Most of the applications are classical HPC simulation workload: typically more write oriented than read oriented, very typical for many HPC applications. They may have relatively few (but very large) data operations. And often the data is arranged for continuous read access, or write access, which is typically fine for HPC applications.
But within the last few years, we also face more and more requests by our AI community users, which has quite different approaches, that typically rely much more on data reads than writes.
The amount of data grows, but also the access pattern switches more to read patterns than just pure write patterns. On the other hand, we do not often see a continuous access pattern anymore. For some applications, we see applications with non-continuous random-access patterns, and also independent shared access by all different computing devices and applications, which makes it more difficult to scale. That was the idea for us to introduce an additional device within our storage software stack. We have, this typical storage path, starting from archive and a large capacity storage tier, which is used for all our applications at different performance levels.
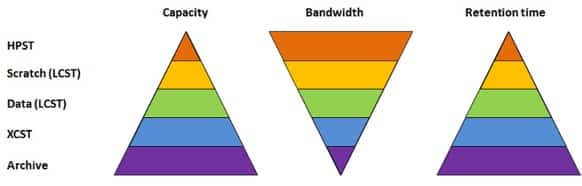
The idea is to introduce something like a cache device here on top of the pyramid, which has a quite small capacity, with a high bandwidth which can act as a burst buffer for classical HPC applications. But it can also serve the needs of the AI community, so we have a process to move the data to this cache before the job starts. Or if you have some data processing project, where data is produced and handed directly into the next step. The data can stay in cache between jobs to be reused efficiently, without needing to be down the pyramid and back up again within the workflow.
This system was designed and delivered by HPE together with DDN, which was funded as part of a Fenix Research Infrastructure project, and it also provides cycles to other interested research scientists to in increase the utilization of this resource, with a total of 110 DDN servers within this HPST (High Performance Storage System), which provides two petabyte of storage.
We use this HPST system as a cache as part of our modular HPC environment, with a nominal bandwidth of two terabytes per second. We directly integrated with our InfiniBand fabric linking all our systems, but our modularity does not just end within a single cluster. We run two modular systems, the JUWELS system and the JURECA system. We also deploy new clusters for different purposes for specific user groups, or also for test systems. We try to connect as much as possible to the same software stack. And this was also a very challenging part here with the help of the DDN research group to build up one global name space for all these different systems, which are connected all to the same HPST, so to the same storage cluster.
System Overview

We are working directly with the research group of DDN to figure out how to evolve the API of the system to help users make efficient use of the system. For example, in the AI community, we have a lot of container-based approaches, which might be more difficult to use when you have a dedicated API.
Terabyte-scale image analysis with HPC-enabled Deep Learning for a building map of the human brain
One interesting example use case is from a group from our neuroscience department in Jülich. They take real human brains, sliced into pieces, and imaged digitally, to build up a kind of atlas for the human brain.
In order to see all the different areas inside the brain, they have developed a system which makes very high-resolution images of those slices. The challenge then is how to deal with these very high-resolution images, and how to identify similar regions in the brain which are connected. They have developed a deep learning approach, but you can imagine we have quite a number of high-resolution images on the system. The problem was that they can only deal with data within a small area, so they have to divide it smaller chunks of data. With an image of 2000 times 2000 pixels, they run deep learning algorithms on those data. The result of this algorithm will be a point within another slice at another position – it’s completely random from the data point of view, which data they need to load next.
As a result, you can’t benefit from any pre-caching mechanism, which might help to speed up the process, which kills the performance if you are using a classical large capacity storage tier. And as we heard in the previous session, having a node level cache will not work, because they still need all the data sets at once. They still need the whole data space available on all the computing notes, and they can’t predict how to distribute the data beforehand. Having this central HPST storage cache helped quite a lot by reducing their access time by a large factor. Even more importantly, it was also much more stable if you compare it to our large capacity storage tier. So from the user point of view, the HPST offers a stable, low latency read access performance.
But AI is only one part of our work, we still have classical HPC simulations where we are focusing on check pointing, working together with people from DDN.
EoCoE-2, the Energy Oriented Center of Excellence
At Jülich, we are working with a number of different scientific models, typically high-energy and physics-oriented applications, and in this example, we are looking at a plasma simulation within a fusion reactor. And of course, for those applications, you typically do some kind of application check pointing after some time, and this is normally wasted time, and we try to speed this up as best as possible.
So, what will be our next steps?
- Start the regular production on the HPST system.
- Further evaluation of this inter-system performance, to demonstrate writing data on one system and reading it on the other one simultaneously
- Integration with SLURM to make this pre-staging of HPST being a part of the job workflow


