For more than a decade, data reduction technologies such as deduplication and compression have been marketed as universal solutions to storage cost and scale challenges. In traditional enterprise workloads, those techniques deliver real value.
But AI has changed the rules.
As organizations build AI inference pipelines powered by massive volumes of unstructured data, many are discovering an uncomfortable truth:
Data reduction provides little to no economic benefit for AI inference. And in some cases, actively works against performance and cost efficiency.
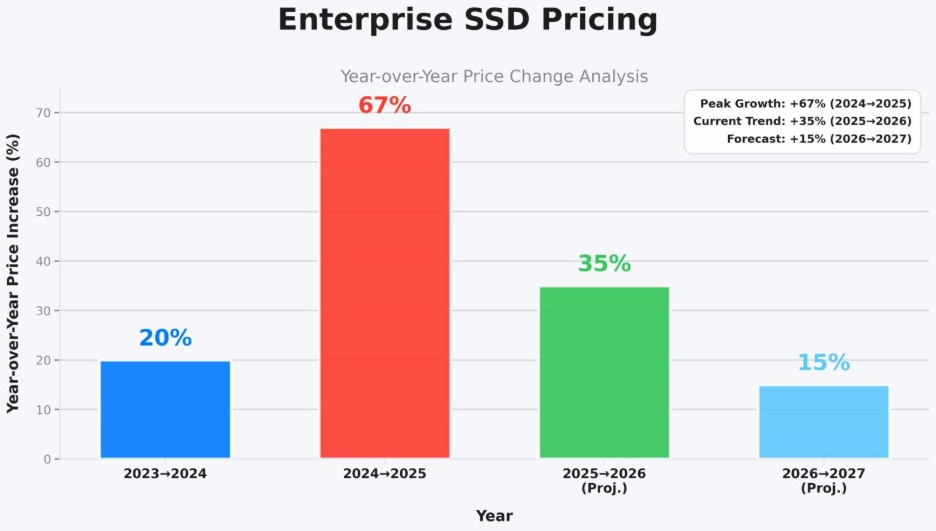
At the same time, dramatic SSD price increases projected for 2026 and beyond are forcing AI architects to re-evaluate long-held assumptions about “all-flash everything.” The result is that more teams are concluding that HDD-based architectures are a viable alternative for many AI inference workloads, especially as SSD price dynamics push greater focus on economics.
The 2026 SSD Pricing Problem
Until recently, many organizations absorbed the inefficiency of all-flash storage because SSD prices were falling fast enough to hide architectural mistakes. That era is ending.
What’s Changing in 2026
- NAND manufacturing consolidation
- Capital intensity of advanced process nodes
- Increased demand from AI training clusters
- Supply constraints driven by hyperscale buyers
The result is material SSD price inflation, particularly for high-capacity enterprise drives. For AI teams building large-scale inference pipelines, this creates a painful reality:
Storing petabytes of low-value, read-heavy inference data on SSD is no longer economically defensible.
What Is Driving the Dramatic SSD Price Increases in 2026 and Beyond?
1. NAND Supply Discipline (Structural, Not Temporary)
NAND manufacturers drastically reduced capacity during the 2022–2023 downturn. Unlike past cycles, they are not racing to overbuild again.
- Fewer fabs
- Tighter wafer starts
- Longer ramp times for new nodes
This creates persistent scarcity, not short-term volatility.
2. AI Training Clusters Are Consuming High-End SSD Supply
Large-scale AI training environments consume:
- High-capacity enterprise SSDs
- Premium endurance SKUs
- Custom-qualified drives
Hyperscalers and frontier AI labs are effectively outbidding enterprises, pulling SSD supply upstream and locking it into long-term contracts.
3. Advanced NAND Is Getting More Expensive to Build
Leading-edge NAND nodes now require:
- More layers
- Higher capital intensity
- Lower yields during ramps
Cost per wafer is rising, and vendors are passing those costs downstream instead of absorbing them.
4. SSDs Are Being Used Where They Don’t Belong
Many AI pipelines, especially inference pipelines store:
- Petabytes of unstructured video and image data
- Cold or warm datasets accessed predictably
- Data that gains no benefit from compression or deduplication
Yet this data is still being placed on SSD because:
- “All-flash” sounds safer
- Legacy assumptions haven’t been revisited
- Data reduction marketing hides true cost
As prices rise, this mismatch becomes impossible to ignore.
5. Inference Pipelines Magnify the Cost Problem
AI inference is not a single workload class and should not be treated as one. Real time inference workflows such as autonomous driving, fraud detection, and recommendation systems require NVMe class latency where milliseconds directly impact the outcome, and HDD is not a viable option in the active inference path.
In contrast, batch inference, large scale video analytics, image processing pipelines, and preprocessing stages are throughput bound rather than latency bound. These workflows operate on persistent, unstructured dataset at petabytes scale, where sustained bandwidth and cost per TB matter more than microsecond latency. In these scenarios, HDD based architecture paired with intelligent caching and high bandwidth networks are not a comprise, they are architecturally and economically correct decisions choices.
Inference workloads are:
- Read-heavy
- Scale-out
- Persistent
- Cost-sensitive
They require bandwidth and capacity, not ultra-low latency.
When SSD prices rise, inference pipelines feel the impact first and hardest—because they scale data volume faster than compute.
The Hidden Cost of Data Reduction in Inference
Even when data reduction produces small capacity gains, it introduces systemic penalties that matter deeply for inference workloads:
- CPU cycles consumed for compression/decompression
- Metadata amplification
- Increased tail latency
- Reduced predictable performance under concurrency
In an inference environment where milliseconds matter, these penalties are often unacceptable.
This is why many AI teams quietly disable data reduction features after deployment even if those features were part of the original buying decision.
Why Deduplication Fails for AI Data
Deduplication relies on finding identical or near-identical data blocks. That assumption breaks down completely with AI data.
Why AI Data Rarely Dedupes
- Two video frames may look similar to humans, but they are not identical at the binary level
- Slight changes in lighting, angle, or motion produce entirely different data blocks
- Image and video datasets are often pre-encoded using formats like JPEG, PNG, MP4, or proprietary codecs
- Feature embeddings and tensors are numerically dense and highly unique
The result?
In practice, many customers see <1.1× dedupe, which is functionally meaningless once metadata overhead and CPU cost are included.
Deduplication ratios for AI inference data are often in the low single digits—or effectively zero.
Why Compression Delivers Minimal Value
Compression suffers from the same fundamental issue.
Most AI data is already compressed at the source:
- Cameras compress video
- Imaging pipelines compress images
- Audio streams are encoded
- ML features are optimized for density
Attempting to compress already-compressed data typically yields:
- Negligible space savings
- Additional CPU overhead
- Increased read latency
- Reduced throughput under load
For inference pipelines where latency consistency and throughput matter more than raw capacity efficiency this is a losing trade.
The Flawed Promise of “Data Reduction at Scale”
Some modern storage vendors continue to position data reduction as a core pillar of AI storage economics. The problem isn’t execution, it’s assumption.
Data reduction assumes:
- Redundant data
- Compressible data
- Capacity efficiency is the primary cost driver
AI inference data breaks all three assumptions.
In real-world AI inference pipelines:
- Data is unique
- Data is already compressed
- Media cost dominates, not logical capacity
No amount of clever metadata or inline processing changes the underlying entropy of video, image, and sensor data. Data reduction is very beneficial for text-based and structured dataset such as log analytics. In the world of AI workflows there can be some benefit for data reduction, but this represents a small portion of the overall data sets leveraged within these pipelines.
The bulk of the datasets are unstructured data that does not benefit from data reduction.
Why HDD Is Re-Entering AI Architectures
HDD is not making a comeback because it is “good enough.” It’s coming back because it aligns with the physics and economics of AI inference data.
Why HDD Fits Inference Workloads
HDD can provide:
- Massive sequential read throughput
- Excellent cost per TB
- Predictable latency at scale
- No dependency on data reduction for economics
- Ideal for large, persistent, unstructured datasets
Especially when paired with:
- Intelligent caching
- Tiered architectures (such as DDN Hot Pools)
- High-bandwidth networks
- Modern parallel file systems
Rising SSD prices expose the fundamental inefficiency of relying on data reduction for unstructured AI data.
As SSD economics worsen:
- Deduplication ratios don’t improve
- Compression gains don’t materialize
- Cost per TB becomes the dominant factor
This is exactly why HDD-based architectures are re-entering AI inference designs, not as a compromise, but as a rational response to physics and economics. HDD-based platforms can feed inference engines efficiently without the cost explosion of all-flash designs.
Designing AI Storage for Reality, Not Marketing
The next generation of AI infrastructure decisions will be driven by economic realism, not legacy enterprise storage thinking.
Smart AI teams are already:
- Separating training vs inference storage
- Using SSD where latency is truly critical
- Deploying HDD where capacity and throughput matter most
- Ignoring data reduction claims that don’t survive measurement
DDN EXAScaler® is aligned to meet customers’ demands, providing the option to leverage SSDs, HDDs or both to design an intelligent solution to meet your performance, capacity and economics requirements. HDDs provide outstanding sequential performance and are great for streaming workloads. SSD accelerates random IO workflows that require low latency.
An EXAScaler cluster with hybrid SSD + HDD drives plus DDN Hot Pools technology can be a highly effective way to keep GPUs maximized during AI inference by aligning each tier to the part of the pipeline it serves best. Inference workflows typically include a mix of hot, latency-sensitive data (active feature sets, indexes, embeddings, model artifacts, and frequently accessed “working sets”) alongside large volumes of colder unstructured content (images, video, sensor data, historical records, and long-tail datasets) that must still be available at scale.
With DDN Hot Pools (a feature built into EXAScaler, no additional software is needed), customers can place the most performance-critical data on SSD for fast access and predictable response times, while using HDD to economically store and stream high-volume unstructured content without forcing the entire environment onto premium flash. This hybrid approach helps ensure high sustained throughput and consistent data delivery to GPU inference nodes, reducing pipeline stalls, minimizing idle GPU cycles, and enabling customers to scale inference capacity in a cost-efficient way as SSD pricing pressures increase.
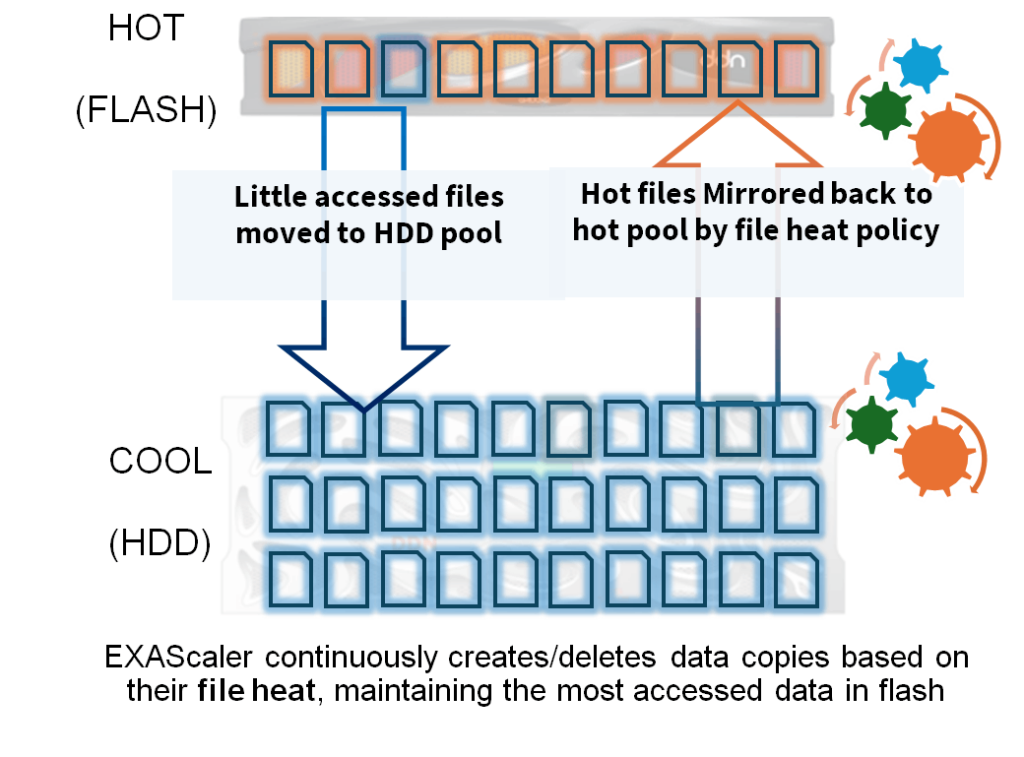
DDN EXAScaler can help organizations architect the right solution for any workflow leveraging the strengths of both drive mediums.
Final Thoughts
AI inference is not a deduplication problem.
It is not a compression problem.
It is a physics, economics, and scale problem.
As SSD prices rise another 30% in 2026, organizations that cling to all-flash, data-reduction-dependent architectures will face escalating costs with diminishing returns.
Those who design around unstructured data reality and embrace the right medium for the right workload will build AI platforms that scale sustainably without breaking the bank.