Key Takeaways:
- Not all AI projects require supercomputer-class infrastructure design, but there are some key areas where traditional IT approaches need to be reconsidered.
- Building an AI Center of Excellence allows you to focus on AI-specific challenges, build expertise, and collaborate between teams while moving towards a new, AI-powered future.
- DDN’s approach to AI Storage is different to traditional storage technologies, because it supports multi-rail data transfers to avoid bottlenecks in high-throughput applications, which drives up the efficiency and throughput of data transfer.
At a recent event, I was debating with customers and partners which was most the important aspect for at-scale systems design: headline performance numbers, certified reference architectures, detailed datasheets – or bringing our expertise to the table to help solve a real-world problem. We all agreed that while the first three are essential proof points, the human touch brings it all together, with real experience to apply technology to create real business value.
In my previous article, How to Train Your Generative AI Dragon, I looked at how Generative AI is much more powerful than creating text or images for enhancing productivity; and our guest author Bob O’Donnell of Technalysis discussed how organizations can activate their AI strategy by mobilizing and harnessing their untapped data, to drive differentiation and innovation at all levels. As we move from idea to implementation, not all AI projects require supercomputer-class infrastructure design, but there are some key areas where traditional IT approaches need to be reconsidered. In this article, I will look at how we bring together the expertise and the technology to help create that unique business value.
As organizations look to move from AI concept to AI implementation, we need to choose a path which will help us deliver on our short-term objectives, while giving a future-proof platform for tomorrow. Every step should be an investment in the future, and so the idea of building an AI Center of Excellence allows us to focus on AI-specific challenges, build expertise, and collaborate between teams as we move towards a new, AI-powered future.
Let’s look at the some of the key focus areas:
Diverse Workload Demands:
I often hear people talk of specialized architectures for AI, emerging software stacks and low-latency networking – and the latest generation of high-performance GPUs, interconnect, and flash memory are clear technology leaders in this respect.
But in practice, we need to focus on the business outcomes, before we make technology decisions: AI is just a different type of workload, and places different demands on compute, networking and storage. The workload is model-dependent, with some models fitting into GPU memory, while others are more I/O dependent. AI, Machine Learning, Deep Learning, Generative AI, Edge AI all represent different styles of workloads, and an AI program may need to draw on different aspects as part of the same long-term strategy.
The Rise of Accelerated Computing
While smaller models can be run on traditional CPU servers, the emergence of high-performance compute accelerators has transformed the scope of AI and machine learning. With many commercial models and frameworks operating on large-scale matrix or graph data structures, the ability to apply parallel operations to large-scale vectors or graph models has placed a premium on fast in-memory capabilities, drawing heavily on graphics and visualization GPU technologies.
The key enabler to this has been the ability to couple clusters of these high-performance GPU accelerators with commercial servers and networking technology, making them easy to integrate and manage within traditional data center architectures – bringing the technology to a much wider audience and opening the door to much greater innovation.
AI Data Storage & the Need for Direct Networking
However, as we saw in previous articles, models and datasets are growing to ever increasing sizes, especially in the field of Generative AI, driven by the desire for greater accuracy, broader vocabulary and richer creativity for a more engaging experience. For example, the latest Large-scale language models (LLMs) such as the original ChatGPT comprises a model size of 175 billion parameters, and the next generation GPT-4 model size is estimated to be 1000x larger.
Model sizes are larger, but training datasets are even larger, and often consist of millions of small files, totalling multiple tens of terabytes or more, rather than a single data extent. With smaller models, it may be possible to fit into GPU memory, which is great for high-speed AI inferencing. However, model training is a very different style of workload, requiring the training data to be loaded and re-loaded hundreds or thousands of times – and for intermediate checkpoint results to be written out frequently.
Traditional storage technologies are limited in throughput, both reads – and especially writes. If a multi-terabyte dataset needs to be READ IN to memory hundreds or thousands of times, then the read throughput becomes an intense bottleneck. But if a terabyte checkpoint can only be WRITTEN OUT at a fraction of the speed, then that can make an AI training cycle unworkable, and a barrier to a successful AI project.
DDN Multi-Rail Technology
DDN’s approach to AI Storage is different to traditional storage technologies, because it supports multi-rail data transfers to avoid bottlenecks in high-throughput applications, which drives up the efficiency and throughput of data transfer. Multi-rail enables grouping of multiple network interfaces on a client system to achieve faster aggregate data transfer capabilities: traffic is balanced dynamically across all interfaces, and links are monitored to detect failure and to automate recovery.
The latest generation InfiniBand (IB) and Ethernet provide both high-bandwidth and low-latency data transfers between applications, compute servers and storage appliances, although Infiniband has become the gold standard in HPC and AI system design, with many-to-many interconnect links to provide a direct connection from client to storage server. However, most storage technologies can only support single-rail transfers, and are unable to utilize the massive bandwidth available in this highly networked configuration.
DDN Optimized Data Paths
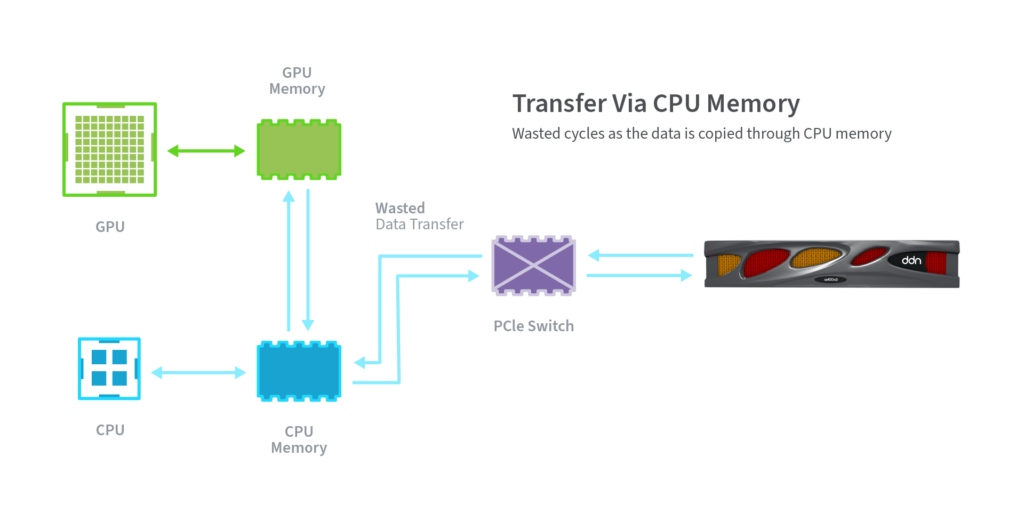
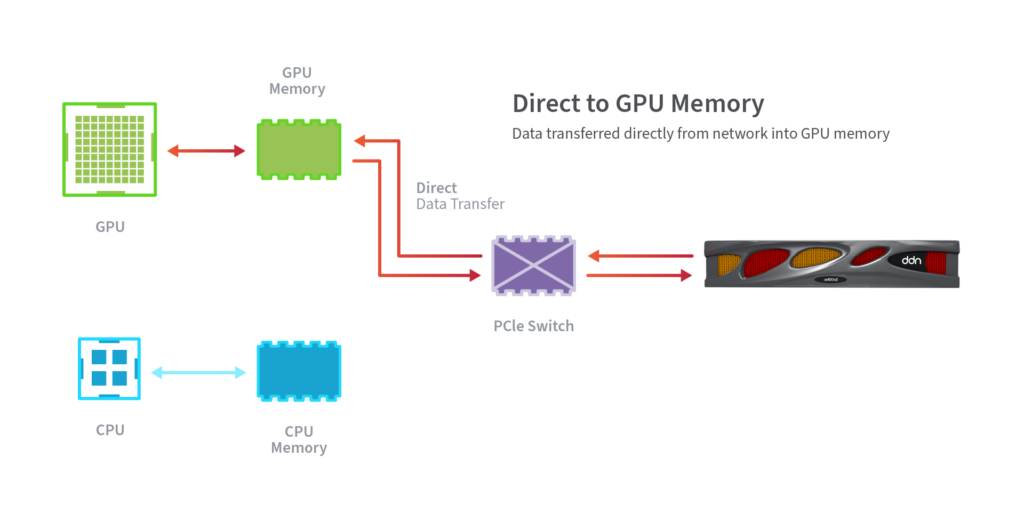
DDN also optimizes the data path, leading to lower latencies and greater efficiencies. For example, while many storage technologies have adopted RDMA (Remote Direct Memory Access) to transfer data to/from system memory, DDN was the first to enable transfer directly into GPU memory, bypassing system memory completely.
This means that not only does the DDN AI400X2 system avoid extra I/O buffer copies, it also avoids copying to and from CPU memory and transferring into GPU memory, streamlining the data path even further.
DDN Hot Nodes
And finally, DDN innovations such as Hot Nodes extend peak performance even further, by automatically caching data on the local NVMe of GPU systems, reducing IO latency and traffic by avoiding network roundtrips. Training models often require datasets to be re-read many times – this multi-epoch learning process places a heavy load on compute, networking and storage. By copying training data into GPU local storage, this frees up networking to serve additional traffic, such as ingest, labelling and archive, driving even greater efficiency.
DDN has encapsulated many years of experience in high-performance system into the latest generation of DDN A3I systems, proven in some of the largest deployments worldwide, backed up with certified reference architectures from our technology and integration partners.
In addition, DDN storage experts can work with you to design a storage architecture which will deliver the best possible performance and efficiency, and support you building your own AI Center of Excellence, as a focus for your teams to share best practice, innovate and collaborate to support your AI initiatives.
Want to learn more about the opportunities created by building your own AI Center of Excellence? Read our Guide to Enterprise AI, written in partnership with NVIDIA and Small World Big Data, and discover how the fusion of cutting-edge technology and strategic vision is shaping tomorrow’s business.