DDN A³I End-To-End Enablement for NVIDIA DGX SuperPOD
DDN A³I solutions (Accelerated, Any-Scale AI) are architected to achieve the most from at-scale AI, Data Analytics and HPC applications running on DGX systems and DGX SuperPOD. They provide predictable performance, capacity, and capability through a tight integration between DDN and NVIDIA systems. Every layer of hardware and software engaged in delivering and storing data is optimized for fast, responsive, and reliable access.
DDN A³I solutions are designed, developed, and optimized in close collaboration with NVIDIA. The deep integration of DDN AI appliances with DGX systems ensures a reliable experience. DDN A³I solutions are configured for flexible deployment in a wide range of environments and scale seamlessly in capacity and capability to match evolving workload needs. DDN A³I solutions are deployed globally and at all scale, from a single DGX system all the way to most of the largest NVIDIA DGX A100 and H100 SuperPOD™ clusters in operation today.
DDN brings the same advanced technologies used to power the world’s largest supercomputers in a fully integrated package for DGX systems that’s easy to deploy and manage. DDN A³I solutions are proven to maximize benefits for at-scale AI, Analytics and HPC workloads on DGX systems.
This section describes the advanced features of DDN A³I Solutions for DGX SuperPOD.
DDN A³I Shared Parallel Architecture
The DDN A³I shared parallel architecture and client protocol ensures high levels of performance, scalability, security, and reliability for DGX systems. Multiple parallel data paths extend from the drives all the way to containerized applications running on the GPUs in the DGX system. With DDN’s true end-to-end parallelism, data is delivered with high-throughput, low-latency, and massive concurrency in transactions. This ensures applications achieve the most from DGX systems with all GPU cycles put to productive use. Optimized parallel data-delivery directly translates to increased application performance and faster completion times. The DDN A³I shared parallel architecture also contains redundancy and automatic failover capability to ensure high reliability, resiliency, and data availability in case a network connection or server becomes unavailable.
DDN A³I Streamlined Deep Learning Workflows
DDN A³I solutions enable and accelerate end-to-end data pipelines for deep learning (DL) workflows of all scale running on DGX systems. The DDN shared parallel architecture enables concurrent and continuous execution of all phases of DL workflows across multiple DGX systems. This eliminates the management overhead and risks of moving data between storage locations. At the application level, data is accessed through a standard highly interoperable file interface, for a familiar and intuitive user experience.
Significant acceleration can be achieved by executing an application across multiple DGX systems in a DGX SuperPOD simultaneously and engaging parallel training efforts of candidate neural networks variants. These advanced optimizations maximize the potential of DL frameworks. DDN works closely with NVIDIA and its customers to develop solutions and technologies that allow widely-used DL frameworks to run reliably on DGX systems.
DDN A³I Multirail Networking
DDN A³I solutions integrate a wide range of networking technologies and topologies to ensure streamlined deployment and optimal performance for AI infrastructure. The latest generation NVIDIA Quantum InfiniBand (IB) and Spectrum Ethernet technology provide both high-bandwidth and low-latency data transfers between applications, compute servers and storage appliances.
DDN A³I Multirail enables grouping of multiple network interfaces on a DGX system to achieve faster aggregate data transfer capabilities. The feature balances traffic dynamically across all the interfaces, and actively monitors link health for rapid failure detection and automatic recovery. DDN A³I Multirail makes designing, deploying, and managing high-performance networks very simple, and is proven to deliver complete connectivity for at-scale infrastructure for DGX SuperPOD deployments.
DDN A³I Advanced Optimizations for DGX H100 System Architecture
The DDN A³I client’s NUMA-aware capabilities enable strong optimization for DGX systems. It automatically pins threads to ensure I/O activity across the DGX system is optimally localized, reducing latencies and increasing the utilization efficiency of the whole environment. Further enhancements reduce overhead when reclaiming memory pages from page cache to accelerate buffered operations to storage. The DDN A³I client software for DGX H100 systems has been validated at-scale with the largest DGX SuperPOD with DGX A100 and H100 systems deployments currently in operation.
DDN A³I Hot Nodes
DDN Hot Nodes is a powerful software enhancement that enables the use of the NVME devices in a DGX system as a local cache for read-only operations. This method significantly improves the performance of applications if a data set is accessed multiple times during a particular workflow.
This is typical with DL training, where the same input data set or portions of the same input data set are accessed repeatedly over multiple training iterations. Traditionally, the application on the DGX system reads the input data set from shared storage directly, thereby continuously consuming shared storage resources. With Hot Nodes, as the input data is read during the first training iteration, the DDN software automatically writes a copy of the data on the local NVME devices. During subsequent reads, data is delivered to the application from the local cache rather than the shared storage. This entire process is managed by the DDN client software running on the DGX system. Data access is seamless and the cache is fully transparent to users and applications. The use of the local cache eliminates network traffic and reduces the load on the shared storage system. This allows other critical DL training operations like checkpointing to complete faster by engaging the full capabilities of the shared storage system.
DDN Hot Nodes includes extensive data management tools and performance monitoring facilities. These tools enable user-driven local cache management, and make integration simple with task schedulers. For example, training input data can be loaded to the local cache on a DGX system as a pre-flight task before the AI training application is engaged. As well, the metrics expose insightful information about cache utilization and performance, enabling system administrators to further optimize their data loading and maximize application and infrastructure efficiency gains.
DDN A³I Multitenancy
Through its built-in digital security framework, DDN A³I software makes it very easy to operate a DGX SuperPOD as a secure multitenant environment. DDN A³I multitenancy makes it simple to share DGX systems across a large pool of users and still maintain secure data segregation. Multi-tenancy provides quick, seamless, dynamic DGX system resource provisioning for users. It eliminates resource silos, complex software release management, and unnecessary data movement between data storage locations. DDN A³I brings a very powerful multitenancy capability to DGX systems and makes it very simple for customers to deliver a secure, shared innovation space, for at-scale data-intensive applications.
DDN A³I Container Client
Containers encapsulate applications and their dependencies to provide simple, reliable, and consistent execution. DDN enables a direct high-performance connection between the application containers on the DGX H100 system and the DDN parallel filesystem. This brings significant application performance benefits by enabling low latency, high-throughput parallel data access directly from a container. Additionally, the limitations of sharing a single host-level connection to storage between multiple containers disappear. The DDN in-container filesystem mounting capability is added at runtime through a universal wrapper that does not require any modification to the application or container.
Containerized versions of popular DL frameworks specially optimized for DGX systems are available from NVIDIA. They provide a solid foundation that enables data scientists to rapidly develop and deploy applications on DGX systems. In some cases, open-source versions of the containers are available, further enabling access and integration for developers. The DDN A³I container client provides high-performance parallelized data access directly from containerized applications on DGX system. This provides containerized DL frameworks with the most efficient dataset access possible, eliminating all latencies introduced by other layers of the computing stack.
DDN A³I S3 Data Services
DDN S3 Data Services provide hybrid file and object data access to the shared namespace. The multi-protocol access to the unified namespace provides tremendous workflow flexibility and simple end-to-end integration. Data can be captured directly to storage through the S3 interface and accessed immediately by containerized applications on a DGX system through a file interface. The shared namespace can also be presented through an S3 interface, for easy collaboration with multisite and multicloud deployments. The DDN S3 Data Services architecture delivers robust performance, scalability, security, and reliability features.
DDN A³I CSI Driver
The DDN CSI driver enables optimized data access for workloads managed by Kubernetes within DGX SuperPOD. The driver provides direct control facilities for the container orchestrator for fully automated storage management. Several types of volumes and data access modes are supported. The driver also enables Kubernetes workloads to dynamically provision and deprovision storage resources based on the workload’s requirements. The deep integration between DDN software and the orchestrator stack ensures most efficient management and utilization of storage resources. DDN engages in continuous software validation with CSI standards to ensure ongoing compatibility and integration of new capabilities as the standard evolves.
DDN A³I Solutions with NVIDIA DGX H100 Systems
The DDN A³I scalable architecture integrates DGX H100 systems with DDN AI shared parallel file storage appliances and delivers fully-optimized end-to-end AI, Analytics and HPC workflow acceleration on NVIDIA GPUs. DDN A3I solutions greatly simplify the deployment of DGX SuperPOD configurations using DGX H100 systems in, while also delivering performance and efficiency for maximum GPU saturation, and high levels of scalability.
This section describes the components integrated in DDN A³I Solutions for DGX SuperPOD.
DDN AI400X2 Appliance
The AI400X2 appliance is a fully integrated and optimized shared data platform with predictable capacity, capability, and performance. Every AI400X2 appliance delivers over 90 GB/s and 3M IOPS directly to DGX H100 systems in DGX BasePOD. Shared performance scales linearly as additional AI400X2 appliances are integrated to DGX BasePOD. The all-NVMe configuration provides optimal performance for a wide variety of workload and data types and ensures that DGX BasePOD operators achieve the most from at-scale GPU applications, while maintaining a single, shared, centralized data platform.
The AI400X2 appliance integrates the DDN A³I shared parallel architecture and includes a wide range of capabilities described in section 1, including automated data management, digital security, and data protection, as well as extensive monitoring. The AI400X2 appliances enables DGX BasePOD operators to go beyond basic infrastructure and implement complete data governance pipelines at-scale.
The AI400X2 appliance integrates with DGX BasePOD over InfiniBand, Ethernet and RoCE. It is available in 60, 120, 250 and 500 TB all-NVMe capacity configurations. Optional hybrid configurations with integrated HDDs are also available for deployments requiring high-density deep capacity storage. Contact DDN Sales for more information.
DDN Insight Software
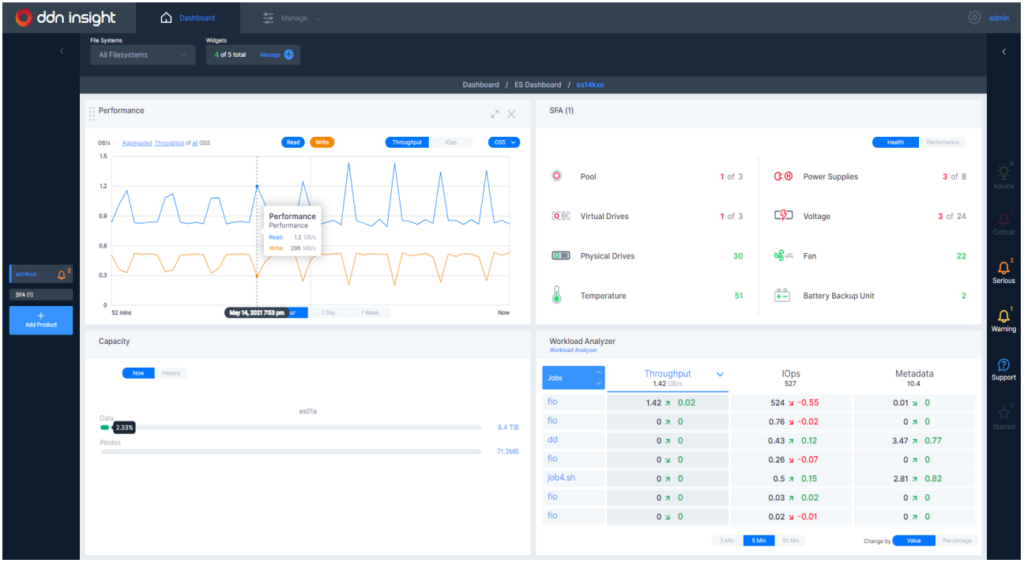
DDN Insight is a centralized management and monitoring software suite for AI400X2 appliances. It provides extensive performance and health monitoring of all DDN storage systems connected to DGX BasePOD from a single web-based user interface. DDN Insight greatly simplifies IT operations and enables automated and proactive storage platform management guided by analytics and intelligent software.
Performance monitoring is an important aspect of operating a DGX BasePOD efficiently. Provided the several variables that affect data I/O performance, the identification of bottlenecks and degradation is crucial while production workloads are engaged. DDN Insight provides deep real-time analysis across the entire DGX BasePOD cluster, tracking I/O transactions from applications running on DGX nodes all the way through individual drives in the AI400X2 appliances. The embedded analytics engine makes it simple for DGX BasePOD operators to visualize I/O performance across their entire infrastructure through intuitive user interfaces. These include extensive logging, trending, and comparison tools, for analyzing I/O performance of specific applications and users over time. As well, the open backend database makes it simple to extend the benefits of DDN Insight and integrate other AI infrastructure components within the engine, or export data to third party monitoring systems.
DDN Insight is available a software-installable package on customer-supplied management servers, and as a turnkey server appliance from DDN.
DDN A³I Recommendations for DGX SuperPOD
DDN proposes the following recommended architectures for DGX H100 SuperPOD configurations. DDN A3I solutions are fully validated with NVIDIA and already deployed with several DGX BasePOD and DGX SuperPOD customers worldwide.
The DDN AI400X2 appliance is a turnkey appliance fully-validated and proven with DGX H100 SuperPOD. The AI400X2 appliances delivers optimal GPU performance for every workload and data type in a dense, power efficient 2RU chassis. The AI400X2 appliance simplifies the design, deployment, and management of a DGX SuperPOD and provides predictable performance, capacity, and scaling. The appliance is designed for seamless integration with DGX systems and enables customers to move rapidly from test to production. As well, DDN provides complete expert design, deployment, and support services globally. The DDN field engineering organization has already deployed dozens of solutions for customers based on the A3I reference architectures.
Recommended Storage Sizing
As general guidance, DDN recommends the shared storage be sized to ensure at least 1 GB/s per second of read and write throughput for every H100 GPU in a DGX SuperPOD. This ensures minimum performance required to operate the GPU infrastructure. All four configurations are illustrated in this guide.
| DGX SuperPOD configuration |
32 DGX H100 |
64 DGX H100 |
96 DGX H100 |
128 DGX H100 |
|---|---|---|---|---|
| Recommended DDN storage | 4 AI400X2 |
8 AI400X2 |
12 AI400X2 |
16 AI400X2 |
| Shared read throughput | 360 GB/s |
720 GB/s |
1 TB/s |
1.4 TB/s |
| Shared write throughput | 260 GB/s |
520 GB/s |
780 GB/s |
1 TB/s |
| Per GPU read throughput | 1.4 GB/s |
1.4 GB/s |
1.4 GB/s |
1.4 GB/s |
| Per GPU write throughput | 1 GB/s | 1 GB/s | 1 GB/s | 1 GB/s |
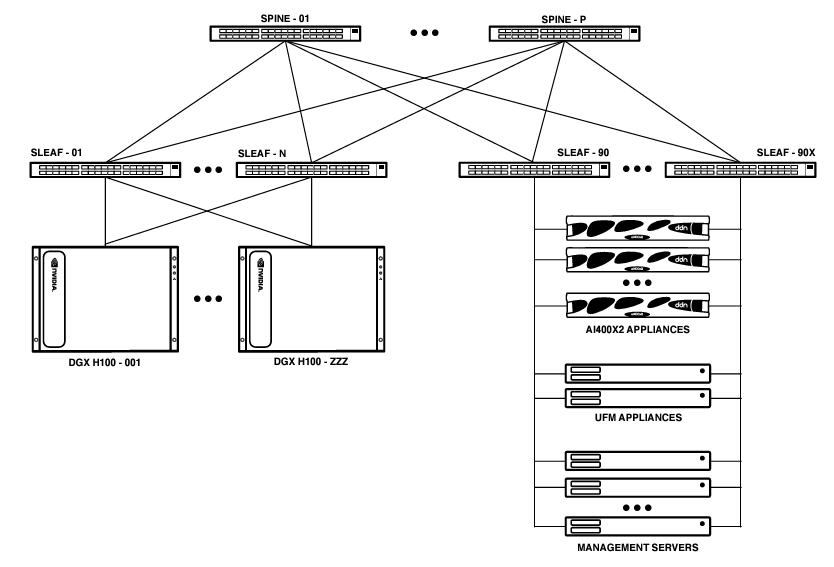
Storage Network for DGX SuperPOD
The DGX SuperPOD reference design includes several networks, one of which is dedicated to storage traffic. The storage network provides connectivity between the AI400X2 appliances, the compute nodes and management nodes. This network is designed to meet the high-throughput, low-latency, and scalability requirements of DGX SuperPOD.
The NVIDIA QM9700 InfiniBand Switch is recommended for DGX SuperPOD storage connectivity. It provides 64 ports of NDR over 32 OSFP ports in a 1RU form factor. DDN recommends the QM9700 switch to deploy DGX SuperPOD. Validated cabling configurations are detailed below.
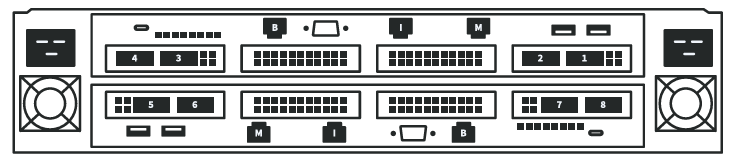
DGX H100 Systems Network Connectivity
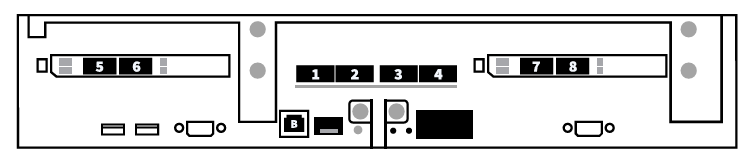
For DGX SuperPOD, DDN recommends ports 1 to 4 on the DGX H100 systems be connected to the compute network. Ports 5 and 7 should be connected to the in-band management network, which also serves as the storage network for Ethernet storage configurations. For InfiniBand storage configurations, ports 6 and 8 should be connected to the InfiniBand storage network. As well, the management BMC (“B”) port should be connected to the outof-band management network.
AI400X2 Appliance Network Connectivity
For DGX SuperPOD, DDN recommends ports 1 to 8 on the AI400X2 appliance be connected to the storage network. As well, the management (“M”) and BMC (“B”) ports for both controllers should be connected to the out-of-band management network. Note that each AI400X2 appliance requires one inter-controller network port connection (“I”) using short ethernet cable supplied.
AI400X2 Appliance Cabling with NDR 400Gbps InfiniBand Switches
The AI400X2 appliance connects to the DGX SuperPOD storage network with 8 200 Gbps InfiniBand interfaces. Particular attention must be given to the cabling selection to ensure compatibility between different InfiniBand connectivity and data rates. DDN and NVIDIA have validated the following cables to connect AI400X2 appliances with QM9700 switches. The use of splitter cables ensures most efficient use of switch ports.
Direct Attached Passive Copper Cables
| MCP7Y60-Hxxx 980-9I46K-00Hxxx |
NVIDIA DAC 1:2 splitter, InfiniBand 400Gb/s to 2x 200Gb/s, OSFP to 2x QSFP56 xxx indicates length in meters: 001, 01A (1.5m), 002 |
Requires 4 cables per AI400X2 appliance.
Active Optical Cables
| MFA7U10-Hxxx 980-9I117-00Hxxx |
NVIDIA AOC 1:2 splitter, InfiniBand 400Gb/s to 2x 200Gb/s, OSFP to 2x QSFP56 xxx indicates length in meters: 003, 005, 010, 015, 020, 030 |
Requires 4 cables per AI400X2 appliance.
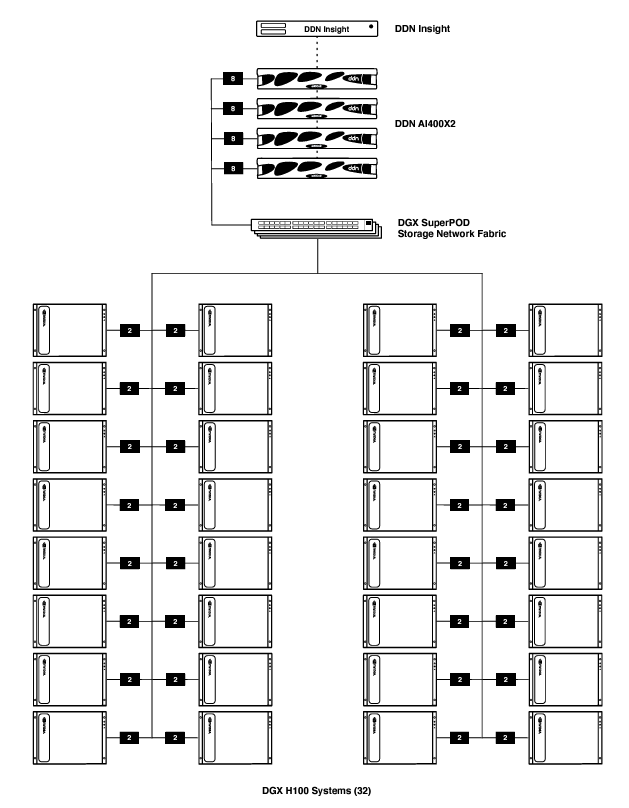
DGX SuperPOD with 32 DGX H100 Systems
Below illustrates the DDN A³I architecture for DGX SuperPOD with 32 DGX H100 systems, 4 DDN AI400X2 appliances and a DDN Insight server. Every DGX H100 system connects to the storage network with two NDR 400Gb/s InfiniBand links. Each AI400X2 appliance connects to the storage network with 8 InfiniBand links using the appropriate cable type. The DDN Insight server connects to the AI400X2 appliances over the 1GbE out-of-band management network. It does not require a connection to the InfiniBand storage network.
DGX SuperPOD with 64 DGX H100 Systems
Below illustrates the DDN A³I architecture for DGX SuperPOD with 64 DGX H100 systems, 8 DDN AI400X2 appliances and a DDN Insight server. Every DGX H100 system connects to the storage network with two NDR 400Gb/s InfiniBand links. Each AI400X2 appliance connects to the storage network with 8 InfiniBand links using the appropriate cable type. The DDN Insight server connects to the AI400X2 appliances over the 1GbE out-of-band management network. It does not require a connection to the InfiniBand storage network.

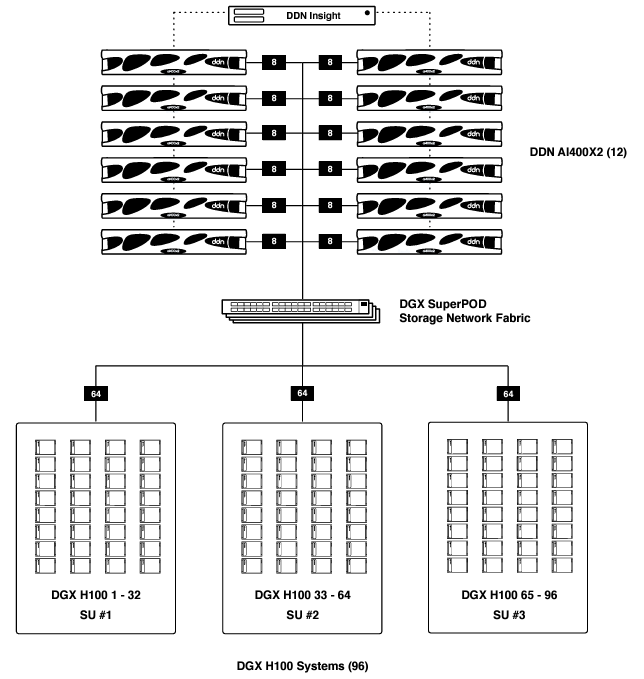
DGX SuperPOD with 96 DGX H100 Systems
Below illustrates the DDN A³I architecture for DGX SuperPOD with 96 DGX H100 systems, 12 DDN AI400X2 appliances and a DDN Insight server. Every DGX H100 system connects to the storage network with two NDR 400Gb/s InfiniBand links. Each AI400X2 appliance connects to the storage network with 8 InfiniBand links using the appropriate cable type. The DDN Insight server connects to the AI400X2 appliances over the 1GbE out-of-band management network. It does not require a connection to the InfiniBand storage network.
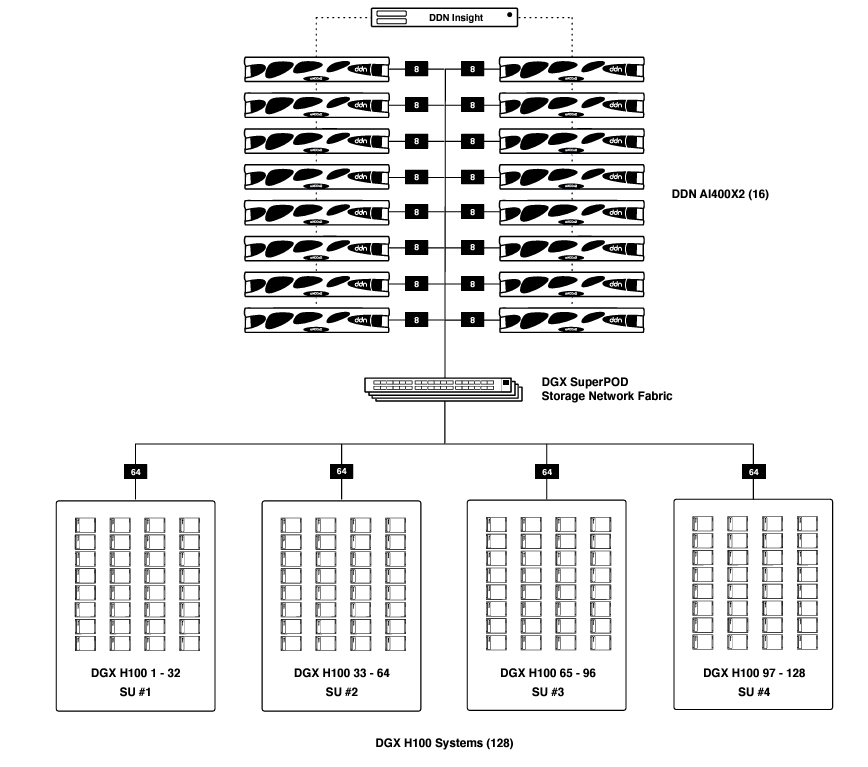
DGX SuperPOD with 128 DGX H100 Systems
Below illustrates the DDN A³I architecture for DGX SuperPOD with 128 DGX H100 systems, 16 DDN AI400X2 appliances and a DDN Insight server. Every DGX H100 system connects to the storage network with two NDR 400Gb/s InfiniBand links. Each AI400X2 appliance connects to the storage network with 8 InfiniBand links using the appropriate cable type. The DDN Insight server connects to the AI400X2 appliances over the 1GbE outof-band management network. It does not require a connection to the InfiniBand storage network.