By James Coomer, DDN Senior Vice President of Products
Another AI benchmark was published this week heralding much confusion! (TL; DR – DDN delivers the highest performance efficiency!)
MLCommons is an organisation that measures the accuracy, safety, speed and efficiency or AI technologies, and this week they published a set of benchmarks intended to provide a level playing field for measuring storage performance for AI (https://mlcommons.org/benchmarks/storage/)
But the results are not simple to interpret, so let me describe how it works.
There are two divisions of benchmark, but the most popular and most interesting is the “closed” division, where there are fewer variables that different vendors can play with.
Each vendor runs up to four types of AI Training, each of which are simulating the training of four widely available AI models, namely: 3D U-Net (image), ResNet50 (images) CosmoFlow (cosmology parameter prediction) and BERT-large (language processing). Each model comes with a dataset. Note that we are simulating training on GPUs and we are running a data benchmark on CPUs https://ieeexplore.ieee.org/document/9499416 since it would often be difficult to get a hold of the number of GPUs needed to run the benchmark for real.
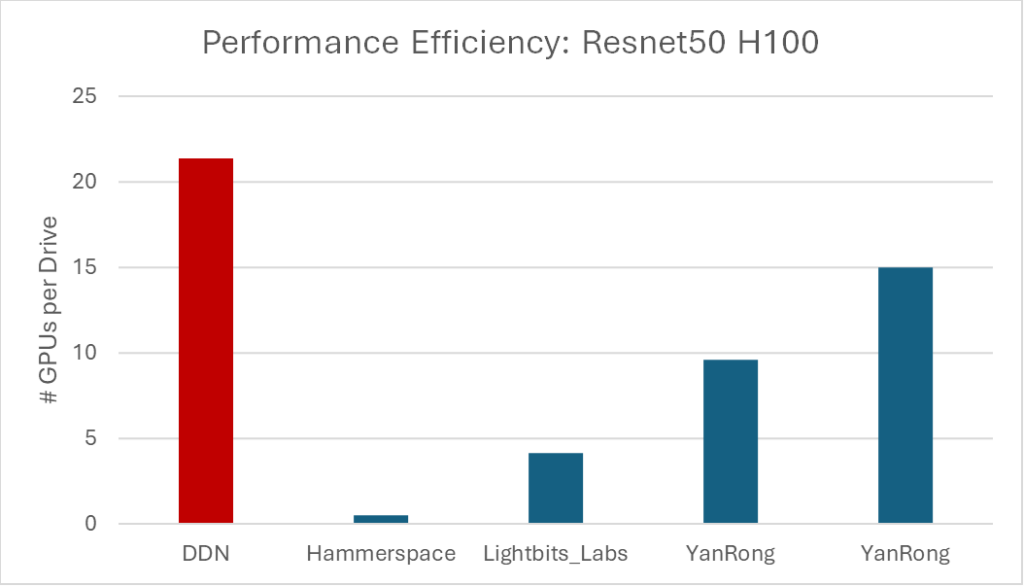
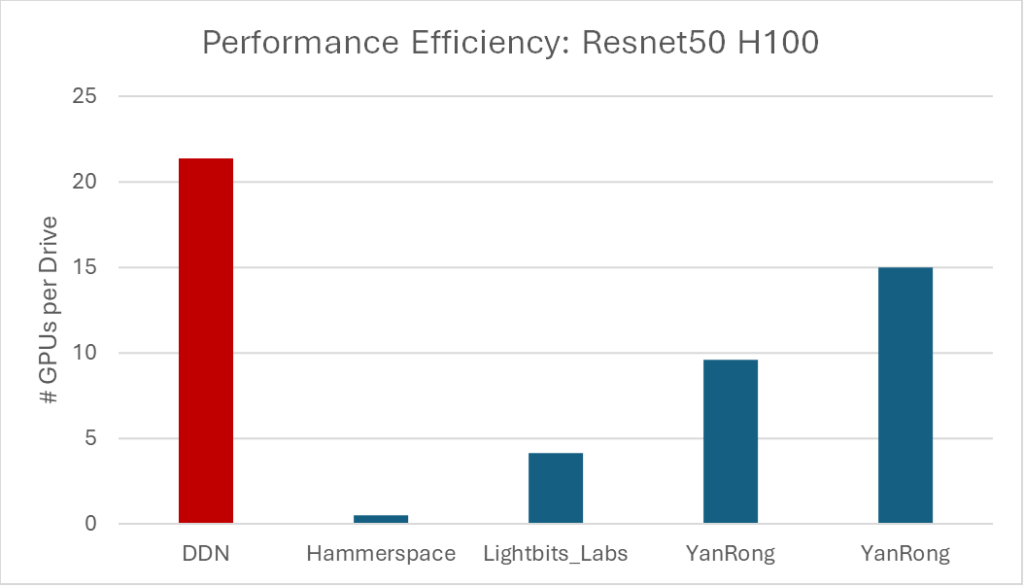
So, let me give you a sneak preview to the results before we go deeper into the methodology. One should ask, “how many GPUs can be powered per SSD/Flash drive?” This makes sense since often the flash media is the largest cost component of flash storage. If we do this and compare all the results from available (released) platforms we get the following and demonstrate the clear leadership of DDN’s performance efficiency:
For the full rules of how to run the benchmark, look here: (https://github.com/mlcommons/storage/blob/main/Submission_guidelines.md) and to see the instructions, look here: https://github.com/mlcommons/storage.
Here is what the benchmark engineer must do, for each of the simulated AI models:
- Choose the number of GPUs that they wish to simulate
- Generate the appropriate dataset for that number of GPUs
- Run the benchmark across a set of computers
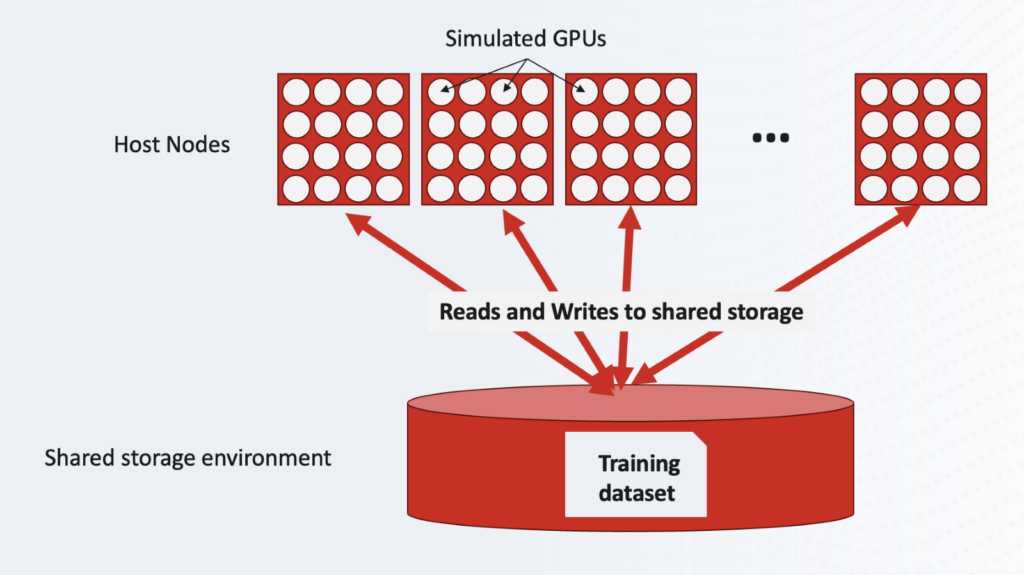
The challenge is this: “How many simulated GPUs can your storage system support?”
For a given storage server configuration, the benchmark engineer will increase and increase the number of virtual GPUs until the benchmark “fails.”
That failure point is set by the benchmark; when the useful work (AU, accelerator utilization) being done by the benchmark drops below a set percentage (90%) of the runtime. This effectively means that around 10% of the time is being consumed by data movements. If the AU drops under 90%, the benchmark is “failed,” and you need to try fewer virtual GPUs until your storage system can support them all within the 90% threshold.
“Accelerator Utilization (AU) is defined as the percentage of time taken by the simulated accelerators, relative to the total benchmark running time. Higher is better.”
The results are published in a table here: https://mlcommons.org/benchmarks/storage/
The interesting columns are:
- Which hardware/software was used for storage
- Which GPU (A100 or H100) – let’s only consider H100, since A100 is quite old now
And then for each of the benchmarks, we report:
- #simulated accelerators
- Dataset size
- Throughput (MiB/s)
From this data, if would make sense to ask, “how much storage hardware is needed to support the #simulated accelerators?” DDN used a single AI400X2 Turbo, which is a 2-rack unit appliance with 24 flash drives.

Looking at DDN’s resnet50 benchmark:
| # simulated accelerators | Dataset Size (GiB) | Throughput (MiB/s) | ||
| DDN | AI400X2T_24x14TiB | 512 | 15680 | 92065 |
A single DDN system with 24 flash drives can support 512 GPUs. Each GPU is demanding, upon average 180 MB/s, but that is not so important – it’s just the amount of data (along with sufficiently low latency of delivery) that is needed to pass the benchmark. Of course, we could have run across fewer virtual GPUs and got higher throughput per GPU. It’s not an interesting metric.
Hammerspace, for resnet50 could support 130 accelerators with a system comprising 2 anvil and 22 storage servers:
| #simulated accelerators | Dataset Size (GiB) | Throughput (MiB/s) | ||
| Hammerspace | 2 Anvil and 22 Storage Servers | 130 | 6400 | 23363 |
The only way really to normalize is to ask, “how much storage hardware is needed on a per GPU basis?” DDN supports 512 GPUs from the two controllers in the AI400X2Turbo. Hammerspace supports 130 from a total of 24 AWS-based VMs.
Alternatively, and back to my earlier point, you could normalize by asking, “how many GPUs can be powered per SSD/Flash drive?” By doing this and comparing all the results from available (released) platforms, we validate the clear leadership of DDN’s performance efficiency: