Building a storage system from one single storage device is straight-forward. Collecting tens of thousands of storage devices and making them appear as a single storage system is extremely difficult. Addressing this challenge successfully for over two decades has made DDN the market leader in data-at-scale. Luckily for those of us who enjoying solving technical problems, there is no resting at the top. With every passing year, systems get larger and creating a virtual distributed storage system becomes more challenging. The scale of the problem is directly related to the number of components in the distributed storage system. The more components there are, the higher the failure rate, and the more difficult it is to transparently mask those failures such that the appearance of a single storage system is unwavering. Although the number of components in a typical storage system has long been growing from year to year, there are two trends recently that have increased this rate of growth.
The first trend contributing to an accelerated growth in the number of components within a typical distributed storage system is that the growth of the individual storage components has slowed.
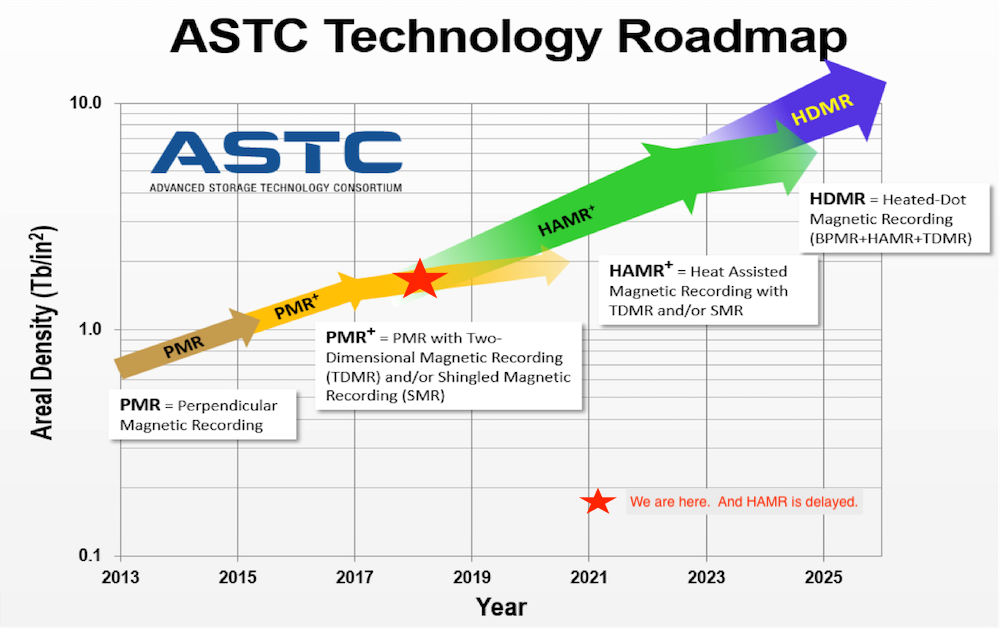
This figure from Seagate[1] shows that hard disk drive capacity growth is constant but unfortunately HAMR is delayed and we are currently in the flattening PMR curve. Therefore, the total number of hard drives in a typical storage system is growing at a faster rate than it used to.
The second trend causing in an increase in the number of components in a typical distributed storage system is that there are more sources of data than previously. Historically, distributed storage systems served as a repository for data produced on computers (e.g. simulation outputs). Recently, however, DDN has seen ever increasing capacity requirements due to additional data streams from sensors, instruments, and the overall Internet of Things. Advancements in artificial intelligence and machine learning contribute to this trend as it is clear that inference accuracy is improved with larger data sets. DDN customers’ demands for ever increasing capacity solutions has been relentless.
These trends imperil our ability to continue creating the illusion of a single storage system from ever increasing number of components. The two scariest problems are that data can be lost, or perhaps even worse, silently corrupted. Therefore, it is DDN’s greatest responsibility, and our greatest source of pride, that we protect our customers from these problems.
To deliver economically balanced products which protect against data loss requires a deep understanding of failure distributions and protection mechanisms. Standard Markov models have long been sufficient for the former and traditional RAID algorithms have long been sufficient for the latter. However, we have now entered a regime in which these are no longer adequate. To address the recently emerging limitations of traditional RAID, all DDN products now ship with industry-leading Declustered Parity Redundancy (DCR). However, the future is murky and may bring even larger systems for which DCR is insufficient. As such, we are embarking now on a study with our fantastic partner Los Alamos National Laboratory (LANL) to ensure our products remain ahead of technology and architectural trends. As Markov models are no longer adequate at this scale, our research will build around simulation studies as well as formal methods to validate the simulations.
LANL recently formed a group called the Efficient Mission Centric Computing Consortium (EMC3) to study problems like these. We at DDN are extremely proud to be selected as the first vendor to join this effort. We will learn a great deal from this research and ultimately provide improved, better performing products for customers.
To learn more about this project, check out this article from LANL or stop by DDN booth #3213 at SC18. This is a really exciting time and we always love the opportunity to partner with our customers, especially when we know it will improve the data center overall.
[1] https://blog.seagate.com/craftsman-ship/hamr-next-leap-forward-now/