This is the second in our series of articles about Checkpointing – click here for previous article
AI training at scale is becoming a critical aspect of the run toward creating AGI and more intelligent and efficient services. From new discoveries to video games to science and medicine, the range of applications is becoming virtually limitless. In the race toward more useful and more intelligent AI systems, high-performance computing (HPC) continues to be the backbone of AI development, with compute performance, storage performance between all tiers, and storage capacity as the three pillars supporting machine learning breakthroughs.
AI training workflows can be segmented into multiple operations that are not limited to computation. Data ingest and preparation, batch reading, model loading, distribution across a cluster, checkpointing of its internal state are examples of a few steps not directly related to the actual computation on GPUs. These operations are quite often IO intensive which can lead to bottlenecks, limiting the average accelerator utilization across the cluster.
Focus on Checkpointing
During an AI training, the model’s entire internal state is saved from time to time on disk, creating jumping-off points to restart from, called checkpoints. Frequent checkpoints can be used to alleviate nodes crashes that can often happen at scale but their use is not limited to fault recovery. Other important reasons for frequent checkpoints include transfer learning if goals change, early stopping if the model starts to deviate or better fine-tuning by picking out less trained states to restart new.
Checkpoint Size & Performance
The size of each checkpoint is coupled with the model’s internal state size, and as AI models have grown by a x1000 factor in three years, this has led to terabytes of data to save per checkpoint during an AI training job. In some cases, this can be partially alleviated by using LoRA, which freeze most of the model parameters, but this method is limited to slight fine-tuning of the behavior of a pre-trained model. A goal change or any SOTA pre-training might need all the neurons, or anything close to that.
Therefore, the write throughput of the storage becomes a critical bottleneck for an AI training job, as frequent checkpoints will typically write a couple of Terabytes of data each time. For example, a paper called “Efficient Large-Scale Language Model Training on GPU Clusters Using Megatron-LM” showed how the checkpointing of a 1 trillion parameter model reached a write throughput of 273GB/s, corresponding to 40% of the peak write bandwidth available.
While this achieved throughput was quite impressive, a thorough analysis of the checkpointing operation shows that the buffered nature of that operation was partially hindering the full potential of the storage.
Hybrid-IO – Unlocking The Full Checkpointing Performance
DDN has been involved in open-source and filesystem development notably through the acquisition of the Lustre filesystem development teams and the software integration into DDN’s EXAScaler, leading to extremely efficient and performant storage solutions for AI. In the last couple of years, work has been done on the filesystem itself to improve the product performance by eliminating bottlenecks. In this goal toward better performance, one of the optimizations that has been developed and that will become available in DDN AI products in 2024 through a software update is called Hybrid-IO.
Hybrid-IO is a filesystem optimization that can determine dynamically if each IO operation should be buffered or not in order to use the fastest path. In many cases it leads to bypassing the Linux pagecache, as it might be a suboptimal choice for a given IO. This selection is done transparently for the user, without needing any code changes, and can improve data streaming performance dramatically, especially for larger block sizes. Both read and write operations get improved. As the buffer is bypassed, it unlocks the bottleneck we described for the checkpointing operation.
AI400X2 + Hybrid-IO – Nearly Doubling The Checkpointing Performance
To verify our claims, we installed a pre-released version of our EXAScaler software containing the hybrid-IO optimization on a DDN AI400X2 appliance. After having connected that appliance to a GPU node, we tested a couple of SOTA AI libraries, such as NVIDIA NeMo and HuggingFace, and we measured the checkpointing performance before and after enabling Hybrid-IO.
Using the NVIDIA NeMo library, we ran the pre-training of a 5B GPT model on that single 8x GPU node and measured the average time it took for the checkpointing operation along with the throughput observed on the network links.
By enabling Hybrid-IO, the write throughput per thread was increased by x1.7 over our previous version of the software during the checkpointing write operation. For the restore operation, meaning the reloading of a checkpoint, we measured a x1.6 speed-up.
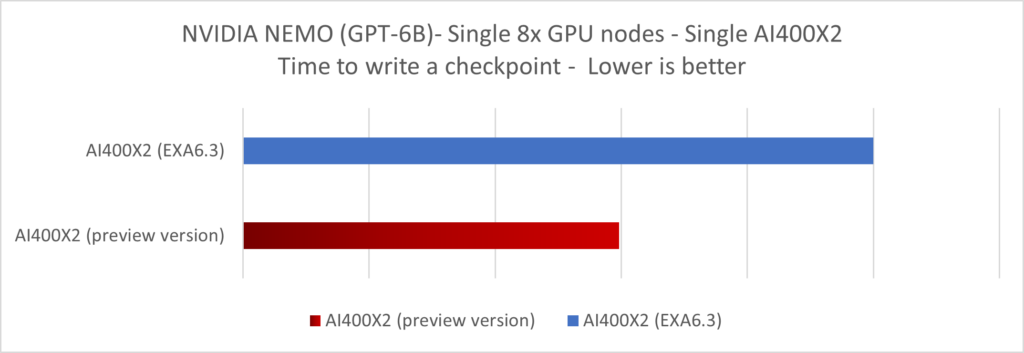
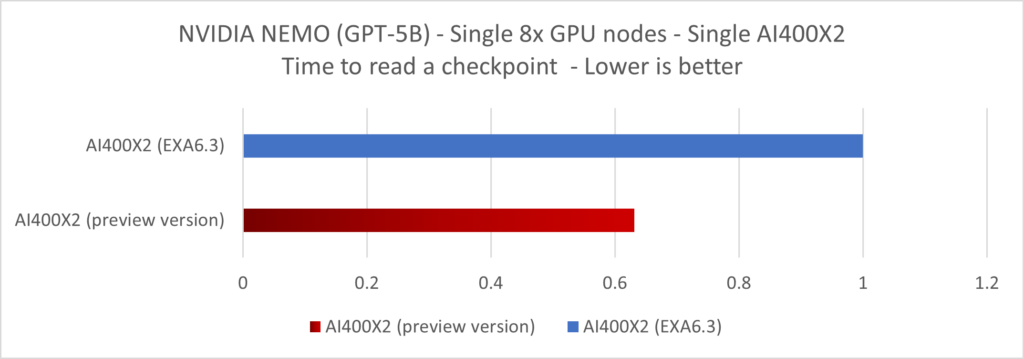
The same measurement was done with other pytorch based library, giving similar results. As a side effect of improving the checkpointing throughput, the AI pre-training wall clock time gets reduced as well. Using HuggingFace and NVIDIA NEMO libraries, we were able to demonstrate an up-to 12% improvement in the wall clock time of a LLAMA2-7B pre-training and up-to 17% for GPT-5B thanks to that Hybrid-IO optimization.
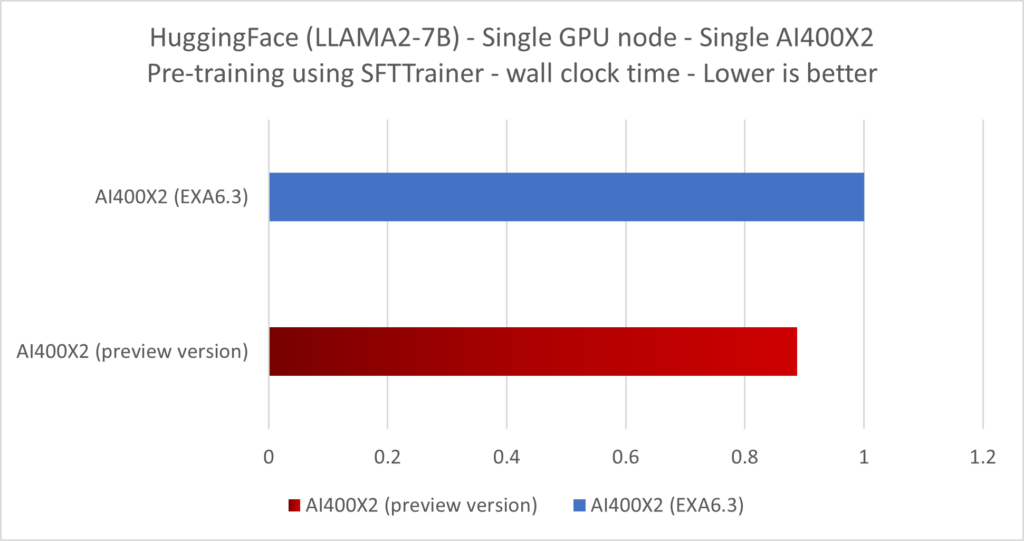
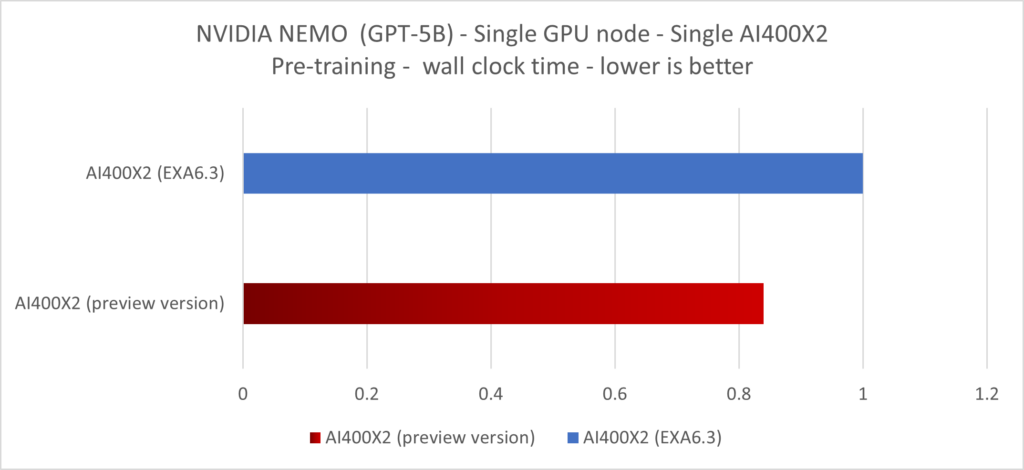
Current Status & Future Improvement
Having unlocked the buffered limitation, DDN is continuing to focus on opportunities for even greater performance with Hybrid I/O. This optimization should be bundled as an EXAScaler software update in 2024 for DDN AI products.
Additional content by Dr. Jean-Thomas Acquaviva and Paul Wallace, DDN