By Moiz Kohari, VP of Enterprise & Cloud Programs
That sinking feeling when you see the S&P 500 drop by 5% on CNBC is enough to make a grown person cry. Now imagine that impact scaled across hundreds of clients whose money you manage. Or worse – you are the global CIO of a top financial institution, explaining to the Federal Reserve what controls were in place and how you are containing the risk. This is not a horror film, it’s a real-world scenario I have watched unfold from the front row.
Risk management and regulatory compliance, done well, help you sleep like a baby. Ignore them, and you’ll be tearing your hair out. Over the holidays, I shared a blog with my LinkedIn community about how to create structured products for risk mitigation. My previous blog was targeted at individuals who want to bulletproof their trading strategies and manage risk in their portfolios. In this article, I will lay out the regulatory landscape and architect an AI-driven solution to navigate market risk for large institutions.
For market operators, the real fear is this: the crash wasn’t external. It was triggered by your own systems. And your compliance algorithms missed it. If your institution precipitated the event – whether through manipulation, error, or omission – you’ll spend the next few days explaining yourself to regulators, the media, and your client base.
Institutional Exposure
Leading exchanges (like Nasdaq, ICE or LSEG) and trading platforms (such as Instinet) are leveraging AI to uphold market integrity and manage risk. These organizations handle massive volumes of trading data in real time, making traditional monitoring impossible. The capability we speak of is not new, in 2016 my team and I developed a machine learning based trade surveillance system for the London Stock Exchange Group. However, the trade volumes and tool sets to help deployments have evolved so significantly that what took us a year to develop today can be deployed in a matter of weeks (if you know what you are doing).
AI-driven market surveillance systems now flag unusual trading patterns, errors, or potential manipulation far more effectively. For example, Nasdaq’s surveillance team reviews over 750,000 alerts annually for anomalies in price movements and trades – a scale that demands machine learning to improve detection efficiency. By incorporating techniques like human-in-the-loop learning, these systems allow compliance analysts to train AI models on the fly, reducing noise and false alarms while focusing human expertise on truly suspicious cases (nasdaq.com).
AI-driven models are used in credit risk management (predicting defaults or optimizing credit portfolios) and market risk (high-speed calculation of risk metrics like VaR). From Wall Street trading floors to back-office compliance departments, AI has become indispensable for managing financial risk and complexity. Risk management is not only for exchange operators or trading platform providers, every market participant from banks to wealth managers have an obligation to implement appropriate systems or they are doing a disservice to their clients. Reputational risk in this space destroys companies overnight, where it takes decades to build. Machine learning models forecast market or credit risks more dynamically. Some banks train ensemble models on market data to improve stress testing and scenario analysis. GPU-accelerated risk simulations speed up calculations that used to take hours, enabling more timely risk management.
Data Infrastructure for AI Workloads
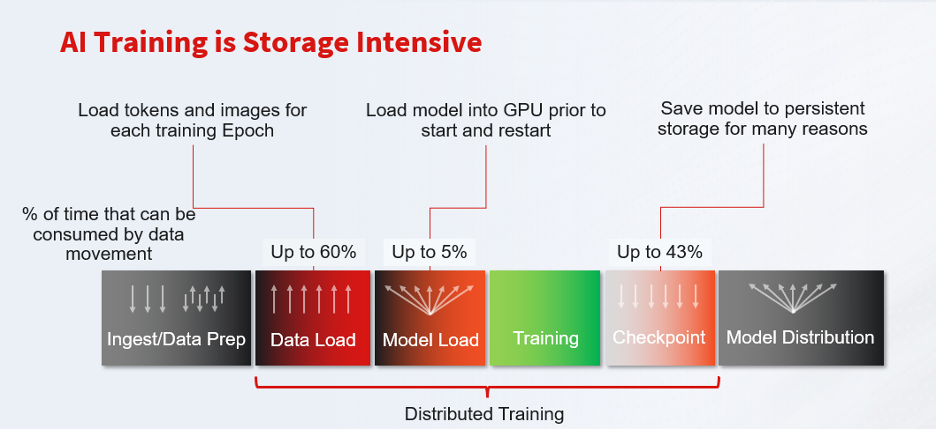
AI workloads in large financial institutions are extremely data-intensive, requiring robust infrastructure to handle ingestion, storage, and retrieval of petabyte-scale datasets. Banks and exchanges ingest streaming market feeds, transaction logs, customer data, and communications that must be stored securely yet remain readily accessible for model training and real-time inference. To support this, firms invest in high-performance data storage platforms that can scale and deliver low-latency throughput. Modern AI-optimized storage solutions (for example, DDN Infinia data platform) are designed to eliminate data bottlenecks in AI workflows. These systems provide massive parallel throughput and tiered storage (flash, object, etc.) to feed data-hungry AI models without delay. In fact, 85 of the Fortune 500 companies run their AI and HPC applications on DDN’s data platforms – a testament to the demand for such high-performance storage in industry. DDN Infinia offers up to 100x faster data access for AI training and can scale from terabytes to exabytes, supporting tens of thousands of GPUs in a single deployment (blocksandfiles.com). It is impossible to deliver business value without the appropriate architecture.
Key requirements for AI-centric storage infrastructure include extreme I/O throughput, horizontal scalability, strong consistency and durability. Financial AI applications often need to simultaneously ingest and process streams of market data and customer transactions. For example, an exchange’s system might capture every order in real time while AI models analyze that data for anomalies. High-performance distributed storage ensures this firehose of data is captured without packet loss and can be processed on the fly. Technologies like NVMe-oF (NVMe-over-Fabrics) and RDMA are used to reduce latency between compute nodes (GPUs) and storage. Vendors have also integrated storage with AI frameworks – for instance, DDN Infinia is integrated with Apache Spark, TensorFlow, PyTorch and NVIDIA’s AI tools to accelerate end-to-end pipelines
This tight integration allows data to flow efficiently from storage to GPU memory (using features like NVIDIA GPUDirect Storage) with minimal CPU overhead. The result is that banks and exchanges can run complex AI models on fresh data in near real-time, which is crucial for time-sensitive risk applications. The result is that DDN Infinia has shown the fastest time to first byte due to the lowest latency access times in the industry.

Model Training Workflows and Data Lifecycle
Developing and deploying AI models in large financial institutions requires carefully orchestrated workflow pipelines. These pipelines ensure that raw data is transformed into insights in a controlled, efficient, and repeatable manner. A typical AI/ML workflow in this industry passes through several stages – from data ingestion to model deployment – with oversight and validation at each step.
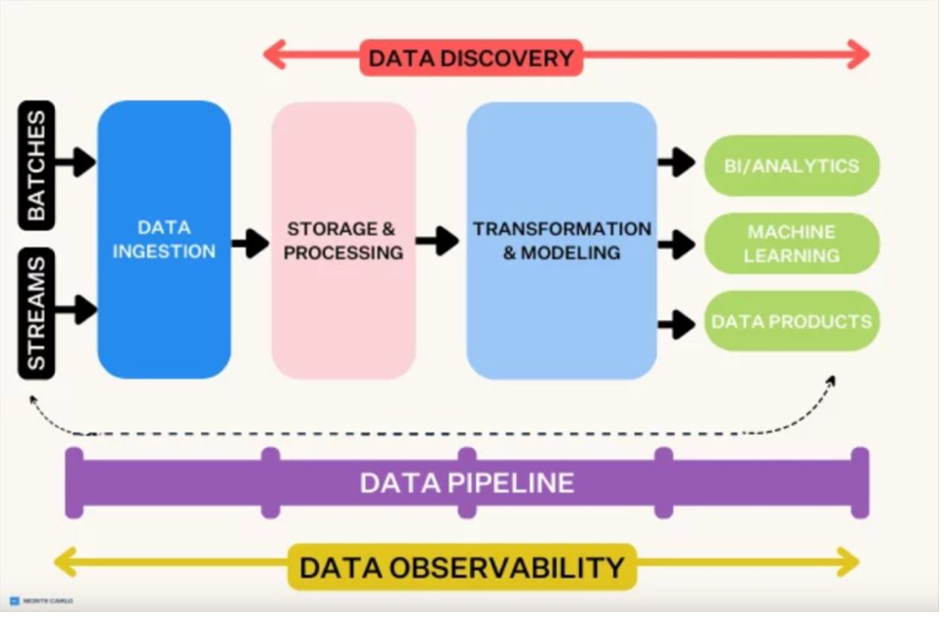
Figure 1: Example of a multi-stage data pipeline architecture, from data ingestion through storage/processing to modeling and outputs. In financial institutions, similar pipelines ingest streaming and batch data (e.g. market feeds, transactions), store and process it in high-performance systems, then transform it into features to feed machine learning models and analytics. “Data discovery” (understanding and cataloging data) and “data observability” (monitoring data quality in production) are layered across the pipeline to ensure transparency and reliability.
In a financial context, such a pipeline might work as follows:
Data Ingestion Layer: Data from various sources is continuously ingested into the system. This could include trading data from exchange feeds, customer account data from internal databases, reference data (like security master or economic indicators), and even unstructured data like news or social media sentiment. Tools like Apache Kafka (for streaming ingest) and batch ETL processes run here. For example, an exchange’s pipeline will have a Kafka stream capturing every trade tick, while a bank might use batch jobs to pull daily customer balances. Key considerations at this stage are low-latency capture (so no data is missed) and initial validation (rejecting blatantly bad records early).
Data Processing and Feature Engineering Layer: In this stage, raw data is transformed into a form suitable for analysis by AI models. This often involves joining different data sources (e.g. linking trades with associated client data or market context), cleaning the data as discussed, and creating features. Feature engineering can be as simple as calculating daily aggregates, or as complex as generating statistical indicators (volatilities, averages) or network graph features for each entity. Financial institutions frequently use distributed processing frameworks like Apache Spark for these heavy data crunching tasks. At the end of this layer, you have datasets and features ready for modeling – for example, a table of customer accounts with 50 feature columns summarizing each account’s behavior. Given privacy and compliance importance, any personal data might be anonymized here if not needed for modeling.
Model Training and Validation Layer: Here, data scientists experiment with and train AI/ML models using the features prepared. This is the core AI Model Layer of the architecture. Data scientists may train a variety of model types – e.g. a gradient boosting model for credit risk, a deep neural network for fraud detection, or even an internal foundational LLM fine-tuned on financial text. They often try ensembles or multiple approaches to see which yields the best accuracy while meeting regulatory interpretability requirements. During training, part of the data is held out for validation to ensure the model generalizes well. This phase is iterative: one might tune hyperparameters or engineer new features based on validation results. Importantly, everything is logged – data versions, code versions, parameters – for audit. Many firms apply model governance at this stage: for critical models, an independent model validation team will review the model’s assumptions, performance, and any potential biases (this aligns with regulatory guidance such as SR 11-7 in the US for model risk management). The best-performing model that passes validation is then prepared for deployment.
Deployment and Integration Layer: Once a model is approved, it gets deployed into production systems. The Integration Layer connects the model with live data and business applications. In practice, this could mean deploying the model as a microservice behind an API, so that other systems (like a trading platform or a compliance dashboard) can query it in real time. This layer also includes model management aspects: version control (so you can roll back to a previous model if needed), A/B testing (running a new model in shadow mode alongside the old to compare outputs), and CI/CD pipelines for models (to automate retraining and redeployment when new data is available, or concept drift is detected).
Application and Monitoring Layer: Finally, the outputs of the AI model are delivered to end-users or systems in the Application Layer. This could be a dashboard that risk managers use to see the model’s alerts (e.g., a compliance officer’s interface showing suspicious trades flagged by the model). In parallel, a monitoring system tracks the model’s performance in production. This includes technical monitoring (latency, errors) and analytic monitoring (data drift, model accuracy over time). For instance, if an AML model that used to flag 100 suspicious transactions a day suddenly drops to 10 or rises to 1000, the monitoring system would alert the data science team to investigate – perhaps the data distribution changed or there is an issue. Logging and audit trails are critical here too: every prediction the model makes is typically stored with a timestamp and the model version, so that any decisions can be later explained or reproduced. Additionally, many firms implement explainable AI techniques at this layer: for each alert or score, the system might generate an explanation (which features contributed most to a particular risk score) to satisfy regulators’ demand for transparency.
Lifecycle Management: The data and model lifecycle doesn’t end at deployment. Firms schedule regular model retraining (for example, retraining a credit risk model quarterly as new default data comes in or retraining a fraud model as fraud patterns evolve). They maintain a model inventory as part of governance – each model has a lifecycle status, from development to active production to decommissioning. Data lifecycle is also managed: raw data might be archived after X years, features might be recomputed with updated logic over time, etc., all under retention policies compliant with regulations. A continuous feedback loop is in place: outcomes of model decisions (e.g., was a flagged trade later confirmed as illicit by investigators?) are fed back to improve the model over time, embodying a learning system.
The above model training workflow in big financial institutions is an industrialized process. It treats data and models almost like an assembly line – raw materials (data) come in, get refined (cleaned/features), get assembled into a product (the model), which is then delivered and monitored, with quality checks at each station. This pipeline perspective is crucial for scaling AI in a regulated environment, because it brings structure, repeatability, and transparency.

Which Model When?
Financial institutions employ a variety of AI/ML models, each suited to different tasks in the risk and compliance lifecycle. Early in the process, models often focus on anomaly detection and pattern recognition in data streams, whereas later stages might use AI to interpret or summarize information for human decision-makers. Below are the common types of AI/ML models in use and where they typically play a role:
- Supervised Learning Models for Classification: These are workhorse models for many compliance use cases, trained on labeled examples of good vs bad outcomes. For instance, a bank might use a gradient boosted decision tree or a neural network to classify transactions as fraudulent or not fraudulent. Similarly, trades can be classified as suspicious (insider/market abuse) or normal based on historical cases. Supervised models excel in scenarios where past examples of risk events are available to learn from. They output risk scores or alert flags that directly feed into compliance workflows (like generating a Suspicious Activity Report for AML). Banks often start with simpler models (logistic regression) for transparency, but over time have incorporated more complex models (random forests, XGBoost, deep learning) as they demonstrate higher accuracy. A key at this stage is reducing false positives while catching as many true issues as possible – a balance that AI has improved by analyzing more signals than a rule-based system could.
- Unsupervised and Anomaly Detection Models: Not all risks are known in advance; new fraud patterns or market manipulation techniques emerge that were never in the training data. Unsupervised models address this by learning the “normal” pattern of data and flagging deviations. Clustering algorithms can identify groups of similar customers or trading days, and anything falling outside those clusters is flagged as an outlier. In practice, these models are used as early warning systems – for example, an unsupervised model might highlight that a particular trader’s activities are statistically different from their peers, prompting a closer look.
- Deep Learning Models: Deep neural networks (including CNNs, RNNs, and GNNs) have found niche but growing use in finance risk and compliance. They are powerful at capturing complex, non-linear relationships in data. For example, Graph Neural Networks (GNNs) treat transactions and entities as a network graph and have been shown to improve detection of complex money-laundering rings by evaluating the network holistically rather than each transaction in isolation. Recurrent Neural Networks or Transformers can analyze sequences – useful for modeling how a series of trades over time might indicate manipulation. Deep learning models require more data and computational power, used in credit risk (e.g., to predict defaults using wide arrays of borrower data) and even in portfolio risk (some asset managers use deep models to predict asset price movements or correlations as part of risk forecasting).
- Natural Language Processing (NLP) Models: NLP is crucial in compliance for dealing with text – be it regulations, legal contracts, or communications. Large Language Models (LLMs), like variants of GPT or Bloomberg’s finance-specific GPT, are being explored to assist compliance officers and analysts. One use case is report summarization: compliance teams face lengthy documents (e.g., regulatory updates, internal audit reports, case files for an investigation) and LLMs can summarize these, highlighting key points. Another use case is regulatory intelligence: LLMs fine-tuned on regulatory texts can answer questions like “What are the MiFID II requirements for record-keeping?” by pulling the relevant text – effectively acting as an AI research assistant for compliance departments.
- Generative AI for Automation: Generative AI (which includes LLMs) is also being tested for automating compliance documentation. As noted on State Street’s industry insights, AI can “automate the creation of regulatory filings, investor disclosures and other documentation with exceptional accuracy,” and even adapt to regulatory changes in real time. For example, an AI might draft a quarterly compliance report, pulling in data from various systems and writing it in a narrative form for regulators, leaving the compliance officer to just review and sign off.
- Ensemble Models and Hybrid Approaches: Given the high stakes, financial institutions often use ensembles – combinations of models – to make decisions. An ensemble might combine a rules engine with an AI model, or multiple models together. For instance, an AML system could require that both a traditional rules-based alert and an AI model alert trigger on the same customer to escalate it (this can signifigantly reduce false positives by requiring consensus).
The toolbox of AI/ML models in financial institutions is rich – ranging from basic to cutting-edge. The key is aligning the model choice with the task: fast anomaly flagging, detailed risk estimation, or intelligent summarization each call for different AI approaches. By using the right model at the right stage, banks and exchanges create an AI-driven assembly line: raw data in, actionable insight out.
Accelerating AI Model Training for Risk Analytics
AI model training in finance often involves enormous datasets (market tick data, transaction histories, communications archives) that must be fed rapidly to GPU clusters. Training risk models or fraud detection algorithms means reading terabytes to produce relatively small model artifacts (computerweekly.com). The bottleneck is frequently I/O: traditional storage with serial or NAS (NFS) access can’t keep dozens or hundreds of GPUs saturated, leading to idle expensive hardware and prolonged training cycles. In addition, financial firms need to iterate quickly – time-to-market for new risk models is critical – so slow data loading or frequent pre-processing copies across silos directly hampers innovation. The challenge is to provide massively parallel, low-latency data delivery to the AI training environment, ensuring 100% GPU utilization and eliminating downtime waiting for data.
DDN Infinia attacks these training bottlenecks with a high-performance, parallel I/O architecture purpose-built for AI. It delivers sub-millisecond data access latency and multi-terabyte-per-second aggregate throughput, so even the largest training sets stream to GPUs without delay. DDN Infinia’s engine reads data in parallel across many nodes and disks, unlike legacy storage that forces serial access. This parallelism, combined with support for RDMA and NVIDIA GPUDirect Storage, enables direct data movement from storage into GPU memory without CPU intervention). By leveraging RoCE (RDMA over Converged Ethernet) on NVIDIA Spectrum-X networks, DDN Infinia can even write data directly into GPU memory with zero packet loss, drastically cutting latency. The result is that GPUs remain fully fed with data – DDN’s AI storage solutions have demonstrated the ability to keep GPUs at 100% utilization during training, meaning costly accelerators are never starved waiting on I/O.
DDN Infinia’s massively parallel throughput shows in real-world benchmarks: it can sustain up to 1.8 TB/s of read/write bandwidth and 70 million IOPS in a single cluster, far outpacing conventional enterprise storage. In practice, financial firms have seen model training data access run 33× faster on DDN compared to legacy NFS-based solutions. This I/O acceleration translates to faster model convergence and more training runs per day – e.g. risk models that once took days to train can finish in hours, and teams can iterate more quickly. DDN Infinia’s performance scales linearly as data grows, thanks to its unique parallel architecture that improves performance even as datasets expand. The platform’s efficiency also reduces infrastructure costs – by keeping GPUs busy, organizations need fewer GPU nodes for the same output, and one deployment reported a 10× reduction in power consumption versus less efficient storage. In short, DDN Infinia removes data as the bottleneck in AI model training, allowing financial AI initiatives to achieve maximum throughput and rapid time-to-insight.
Modern Surveillance and Anomaly Detection
In real-time surveillance – such as monitoring trading activity for market abuse or scanning transactions for fraud – financial institutions must ingest and analyze a deluge of data with near-zero latency. Trading platforms, payment networks, and communications channels produce streams of events and messages that need immediate scrutiny by AI models or rules engines. The technical hurdles include high-velocity data ingestion, concurrent processing, and immediate retrievalfor analytics. Any slowdown can result in missed fraud alerts or delayed trade surveillance, which is unacceptable when milliseconds matter. Traditional data pipelines often struggle to keep up: they may serialize writes or overload a single database, causing backlogs during peak volumes (e.g. market open spikes). Ensuring consistent sub-millisecond responsiveness under heavy, parallel workloads is the core challenge here.
Market Abuse Detection: Stock exchanges and regulators now use AI to surveil trading activity across markets in real time. The AI models ingest massive streams of orders and trades, flagging irregular patterns that could indicate insider trading or manipulation. Deep learning techniques are particularly good at spotting subtle, non-linear patterns – e.g. a series of trades spread across multiple brokerages that collectively move a stock’s price (a tactic that might indicate collusion or pump-and-dump schemes). By training on historical examples of known abusive patterns, these models can raise alerts on “lookalike” scenarios in new data. These systems employ transfer learning to quickly adapt models from one market to another, and human-in-the-loop feedback so that compliance officers reviewing alerts continuously improve the algorithms.
Insider Trading & Anomaly Detection: Detecting insider trading is notoriously difficult, as it often involves identifying that a trade was made on non-public information. AI is helping by correlating disparate data sources: trading data, news or corporate announcements, and even natural language processing of employee communications. Some banks have begun using ML models that take in employees’ trades in their personal accounts and compare them against news flows or sensitive information they had access to, looking for statistically unusual advantages. Unsupervised learning methods (e.g. clustering or autoencoders) are also applied to identify outlier behaviors – for instance, a broker whose trading pattern deviates from peers could indicate rogue trading. In practice, firms still rely on specialist teams for insider trading investigations, but AI provides a powerful “early warning system” by narrowing down the massive universe of trading to a manageable set of anomalies that merit human review.
Regulators like the SEC have also invested in such technology: the SEC’s EPS Initiative uses risk-based data analytics to uncover earnings manipulation and insider trading, leading to enforcement actions. These government tools set a baseline that the private sector is expected to meet; if regulators can spot an issue via AI, they expect the firm to have caught it as well.
Surveillance of Communications: Modern regulations require not just monitoring transactions, but also the communications around those transactions. Under EU rules like MiFID II and the Market Abuse Regulation (MAR), financial firms must capture and surveil all communications (calls, emails, chats) that could relate to a trade. AI is invaluable here: natural language processing models scan employee emails, chat logs (e.g. Bloomberg chat, WhatsApp), and voice transcripts for keywords or patterns that suggest collusion, insider information leaks, or other misconduct.
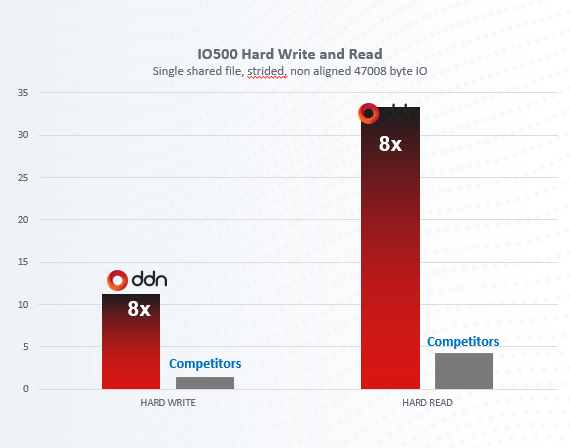
DDN Infinia is engineered for extreme ingest and query performance, making it ideal for real-time surveillance workflows. Its architecture supports massively parallel ingestion, meaning multiple data streams (trades, orders, chat messages, etc.) can be written simultaneously without saturating the system. Unlike conventional storage that might choke on many small writes, DDN Infinia handles immense concurrency – tests have shown it can service over 200,000 data fetches per second using just a 6-node cluster (hpcuserforum.com), a testament to its ability to ingest and retrieve millions of events per second in larger deployments. Critically, it is the first object storage platform to deliver sub-millisecond latencies for writes and reads. This 100× latency reduction compared to typical object stores means that as soon as a trade or transaction is written into DDN Infinia, analytic processes can access it essentially instantly. The platform’s use of RDMA networking ensures that even across a distributed environment, data travels with microsecond-scale hop delays, preserving end-to-end latency under 1 ms for real-time pipelines.
DDN Infinia’s design also avoids performance degradation under unpredictable loads. Its adaptive I/O engine and NVIDIA Spectrum-X integration dynamically route and load-balance network traffic to prevent congestion and jitter. This guarantees consistent throughput even if one market feed suddenly spikes in volume – a common scenario in market surveillance. DDN’s solution has demonstrated deterministic low latency and high throughput in production, translating to true real-time detection capabilities. For example, organizations combining DDN with NVIDIA Spectrum networking have eliminated GPU idle time in streaming inference and maintained smooth 24×7 operations.
Multi-tenancy with QoS further ensures that different surveillance teams or AI models can share the data infrastructure without starving each other – DDN Infinia isolates workloads and automatically manages QoS so that a burst in, say, trade surveillance ingestion does not slow down an AML fraud model reading data at the same time. This is crucial in financial environments where numerous analytic processes run concurrently on the same data reservoir. The net effect is that DDN Infinia allows banks and exchanges to run real-time AI surveillance – detecting rogue trading patterns or fraudulent transactions on the fly – with the confidence that the underlying data pipeline will not lag or lose pace. Potential fraud is identified and stopped before it causes damage, meeting both security and regulatory expectations for immediate response.
Regulatory Context and Compliance Requirements
Any discussion of AI in financial risk and compliance must be grounded in the regulatory context. Financial institutions operate under stringent regulations from bodies in the US, EU, and around the world, and these regulations both mandate certain risk controls and influence how AI can be used. In recent years, regulators themselves have begun leveraging advanced analytics (SupTech – supervisory technology) and they expect firms to do the same (RegTech). Below, we outline the key regulatory drivers in the US and EU and how they frame AI deployments:
United States (SEC & FINRA): In the US, the Securities and Exchange Commission (SEC) and the Financial Industry Regulatory Authority (FINRA) are primary enforcers for securities markets. They require broker-dealers, exchanges, and banks to maintain robust surveillance and reporting systems. For example, FINRA Rule 3110 obliges firms to supervise trading activity and communications to prevent fraud and manipulation. This translates to requirements for automated trade surveillance – an area where AI is now heavily used. FINRA itself has technology to sift through billions of market events for red flags, and it has fined firms (like Instinet, as reported in news) for failing to have adequate surveillance and reporting mechanisms. There’s an implicit expectation that firms use the best tools available (increasingly AI) to detect misconduct. Regulators have explicitly said that if they can catch something with data analytics, firms should be able to as well
In practice, US regulations like the Bank Secrecy Act and Patriot Act (for AML) also drive AI adoption. The Federal Reserve and OCC have guidelines on model risk management (SR 11-7 / OCC 2011-12) that require banks to validate and document their models, including AI models, thoroughly. This means any AI used in a regulatory context must be explainable to some degree and subject to periodic review.
European Union (MiFID II & MAR): The EU’s Markets in Financial Instruments Directive II (MiFID II) and the related Markets in Financial Instruments Regulation (MiFIR) dramatically increased requirements for transparency and surveillance when they came into effect in 2018. MiFID II puts trade surveillance at center stage, aiming to protect investors and market integrity. It requires investment firms, trading venues, and even asset managers to monitor for market abuse (insider trading, market manipulation) and to report suspicious transactions without delay under the Suspicious Transaction and Order Reporting (STOR) regime of the Market Abuse Regulation (MAR). To comply, firms must capture as much data as possible around trades – not just the trade details, but also quotes, order book data, and associated communications. The data trail for a given trade should be detailed enough to allow regulators to reconstruct what happened and determine if the client got a fair deal (best execution) or if any manipulation occurred. This necessitates comprehensive data storage and surveillance algorithms; hence many EU firms turned to AI to handle the complexity. For example, MAR and MiFID II require monitoring all orders (even those not executed) for suspicious patterns, a perfect use case for anomaly-detecting AI.
MiFID II also has specific rules like Article 16(7) which mandates recording all telephone conversations and electronic communications that result in transactions or even those that could have led to a transaction. This means an immense volume of voice recordings, emails, chats must be stored and surveilled. Compliance teams use AI speech-to-text to transcribe calls and NLP to flag keywords (with humans reviewing flagged calls). The requirement to keep these records for five to seven years.
RegTech Alignment: A positive note is that regulators and firms are somewhat aligned in using technology. There’s also an understanding that AI can help manage regulatory compliance costs, which have soared in the past decade. AI-driven automation (like reading new regulations and determining impact) can ease compliance burdens if done right.
Regulatory compliance in finance covers a broad set of data-intensive tasks – from AML (Anti-Money Laundering) pattern detection and trade compliance, to monitoring employee communications (emails, chats, voice transcripts) for misconduct. These processes entail handling high volumes of sensitive data (every transaction, every communication must be stored and scanned) and applying AI or rules to flag issues. The technical challenges include managing diverse data types (structured transaction records vs. unstructured text/audio), ensuring data integrity and security, and performing analytics (searches, pattern matching, NLP inference) at scale. Compliance workloads often involve many small files or records (e.g. millions of chat messages), requiring high IOPS and efficient metadata handling. At the same time, regulators demand strict controls: data must be stored in a tamper-proof manner, with audit trails and long retention. Traditional solutions might use separate archives or databases for different data types, making a unified analysis difficult and increasing complexity. The challenge is to provide a unified, secure data platform that can ingest everything, allow fast AI-powered scans, and meet all compliance retention requirements.
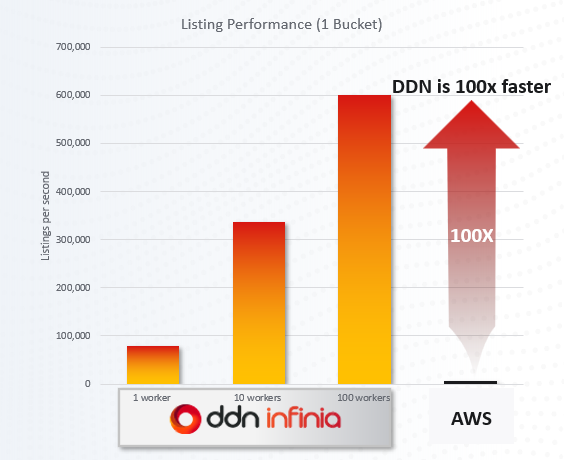
DDN Infinia addresses compliance data challenges by combining high-performance data handling with comprehensive governance features. First, it serves as a unified repository for all data types – capable of ingesting structured data (e.g. trade logs) and unstructured content (documents, chat transcripts) in parallel. This eliminates the need for siloed storage; compliance officers can run analytics across communications and trade data in one place. DDN Infinia’s powerful metadata engine is a game-changer here: each object (email, record, etc.) can carry richly descriptive tags (client ID, case number, risk category, etc.), with support for tens of thousands of tags per object. This means compliance teams can instantly classify and retrieve data – for example, pulling all messages tagged with a certain trader and date range – without brute-force searching. The platform’s metadata indexing and search capability is designed to handle billions of records efficiently, so compliance queries or AI models (like NLP models looking for insider trading keywords) run fast. DDN Infinia’s performance in handling small, random I/O ensures that scanning millions of short records is smooth. With up to 70 million IOPS available, it can support enterprise-scale compliance analytics (such as an NLP model evaluating every communication for policy violations) with capacity to spare.
Crucially, DDN Infinia was built with security and data integrity at its core – a must for regulated data. It provides end-to-end encryption (data in flight and at rest) and supports immutable storage policies. Immutability means once data (like a trade record or email) is stored and locked for compliance, it cannot be altered or deleted until its retention period expires – this meets regulatory requirements for write-once-read-many (WORM) storage. The system’s internal design (with erasure coding, snapshots, and multi-node redundancy) ensures any attempted tampering would be evident and that no single failure can corrupt the data. DDN guarantees five 9’s availability (99.999%) on its platform, so compliance data is essentially always accessible – important for regulators who may perform unexpected audits. Additionally, multi-tenant isolation in DDN Infinia allows compliance departments to have a segregated logical view of the data with customized access controls, while still benefiting from the shared performance of the global platform. Built-in QoS means that heavy compliance workloads (e.g. a full historical scan for an SEC inquiry) can run without impacting other critical operations.
From a quantitative standpoint, adopting DDN for compliance monitoring yields tangible improvements. For instance, an AML investigation that requires searching across terabytes of transactions and customer data can be completed much faster when the data is all in one high-speed platform (as opposed to querying multiple slow archives). While specific speedup depends on the use case, DDN’s parallel architecture has been shown to drastically cut data access times – one case saw complex queries run dozens of times faster than before. More importantly, DDN ensures that compliance becomes a continuous, real-time process rather than a periodic batch job: AI models can continuously ingest and analyze data for red flags, knowing the storage layer can keep up. By marrying performance with governance, DDN Infinia not only helps catch fraud and compliance breaches quicker, but it does so in a manner that satisfies auditors and regulators. This level of trust and speed is invaluable for financial institutions under stringent oversight.
Conclusion and Future Outlook
AI has transitioned from a novel experiment to a mission-critical component of risk management and compliance in large financial institutions. Exchanges, banks, and other financial players have demonstrated that AI can strengthen market integrity, detect fraud and anomalies faster, and ensure compliance in a highly complex regulatory landscape. CIOs driving these initiatives are effectively enabling their organizations to manage risk proactively rather than reactively. They are also automating labor-intensive compliance tasks, freeing up human experts to focus on judgement-intensive decisions.
AI’s role in risk and compliance is not about replacing human judgment, but amplifying it. It allows institutions to monitor the large“forest” of financial activity while still being able to drill down to individual “trees” that need attention.
Investing in modern AI and data infrastructure is investing in the resilience and integrity of your institution. The technology, from high-performance storage to GPU-accelerated analytics to advanced machine learning models, is ready and mature. The institutions that put these pieces together wisely will lead in the new era of AI-assisted finance, where risk management is smarter, compliance is continuous, and trust in the financial system is reinforced by the very data that flows through it.
Interested in learning how DDN can support your risk management strategy?
Get a complimentary risk and infrastructure assessment – no strings attached.